





Stable Diffusion: LoRA selfie

Je kunt je eerste dataset maken met een eenvoudige camera en een vrij uniforme achtergrond, zoals een witte muur of een monotoon verduisteringsgordijn. Voor een voorbeeld dataset heb ik een spiegelloze camera Olympus OM-D EM5 Mark II met 14-42 kitlenzen gebruikt. Deze camera ondersteunt afstandsbediening vanaf elke smartphone en een zeer snelle continue opnamemodus.
Ik heb de camera op een statief gemonteerd en de scherpstelprioriteit ingesteld op gezicht. Daarna selecteerde ik de modus waarin de camera elke 3 seconden 10 frames achter elkaar vastlegt en startte het proces. Tijdens het fotograferen draaide ik mijn hoofd langzaam in de geselecteerde richting en veranderde na elke 10 beelden van richting:

Het resultaat was ongeveer 100 frames met een monotone achtergrond:
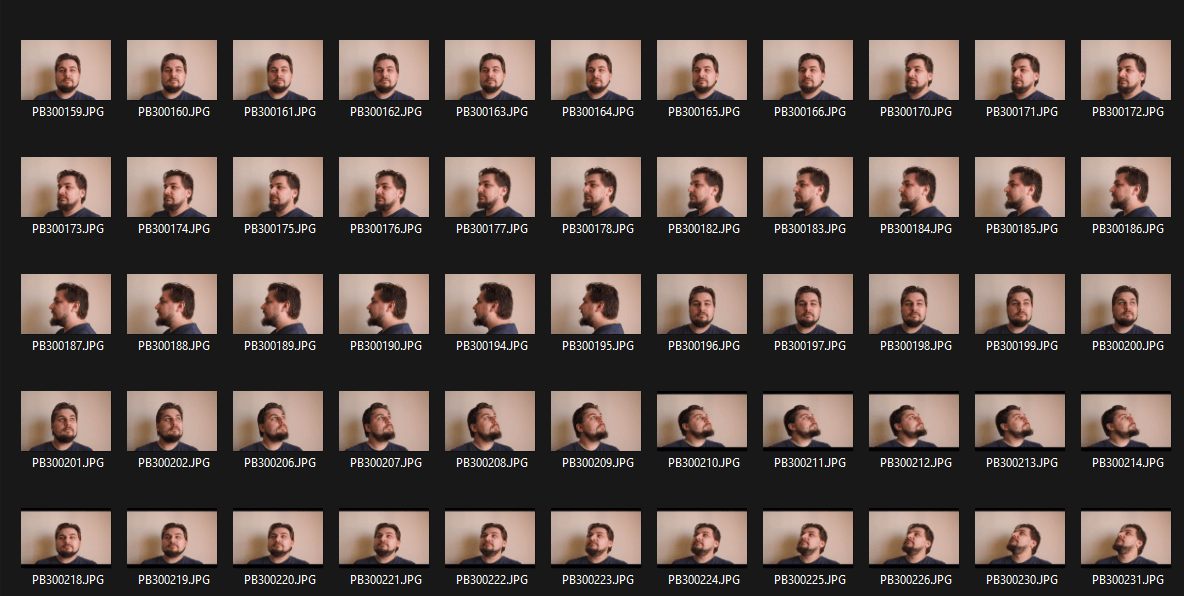
De volgende stap is om de achtergrond te verwijderen en het portret op een witte achtergrond te laten staan.
Achtergrond verwijderen
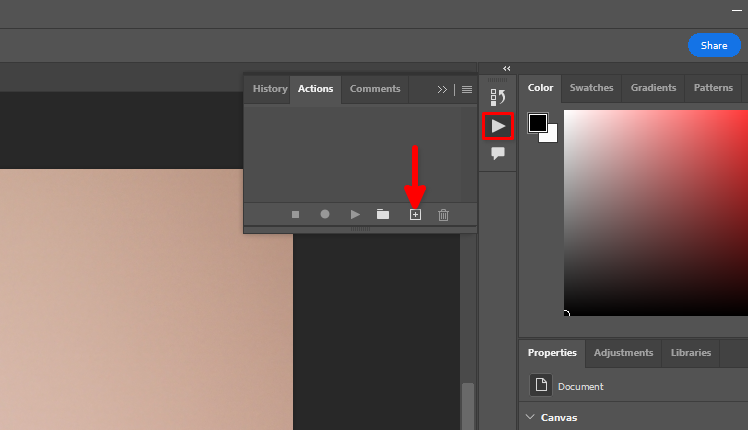
Je kunt de standaard Adobe Photoshop Remove background functie en batchverwerking gebruiken. Laten we acties opslaan die we op elke foto in een dataset willen toepassen. Open een willekeurige afbeelding, klik op het driehoekpictogram en vervolgens op het + symbool:
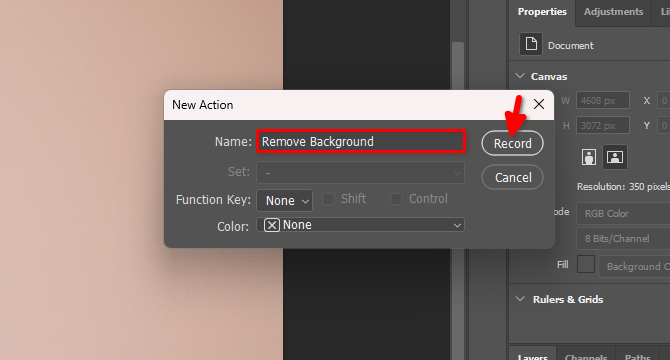
Typ de naam van de nieuwe actie, bijvoorbeeld Remove Background en klik op Record:
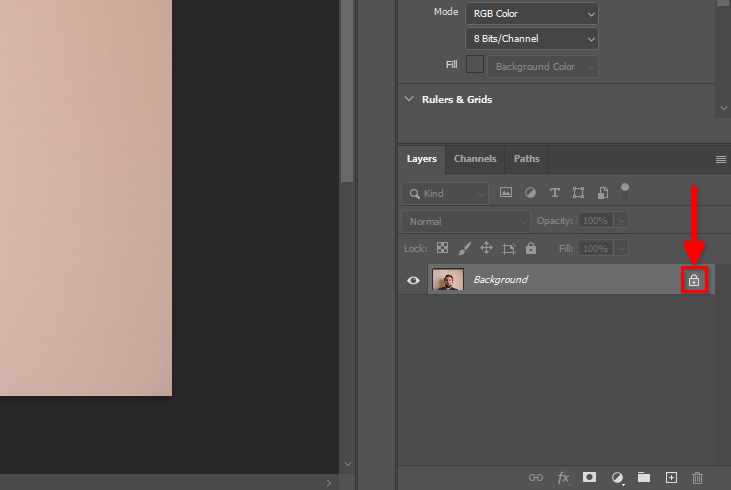
Zoek op het tabblad Layers het slotsymbool en klik erop:
Klik vervolgens op de knop Remove background op het zwevende paneel:
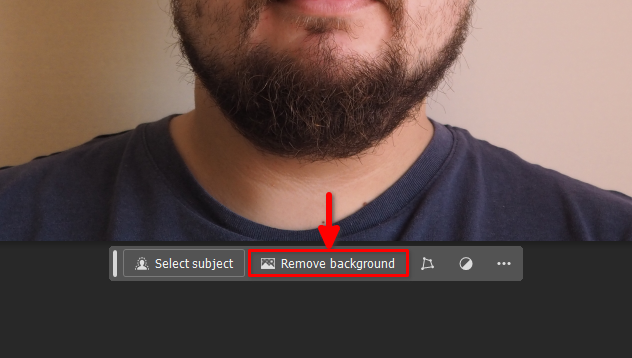
Klik met de rechtermuisknop op Layer 0 en selecteer Flatten Image:
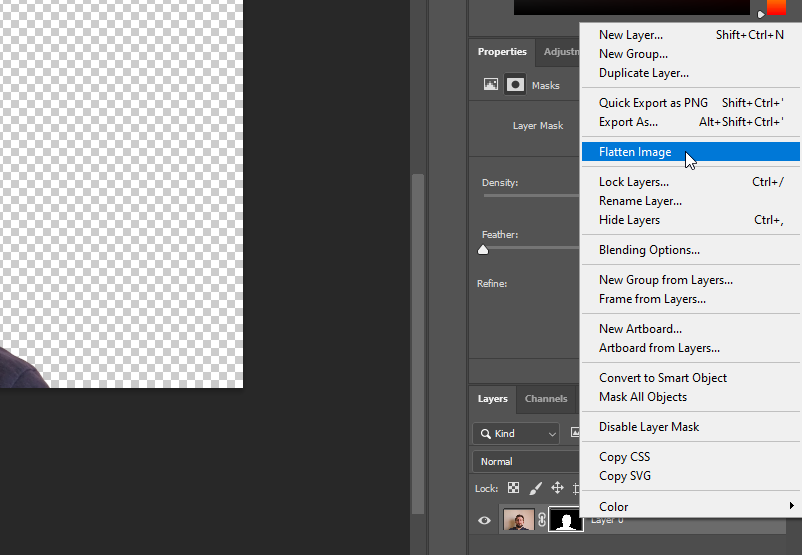
Al onze acties zijn opgenomen. Laten we dit proces stoppen:
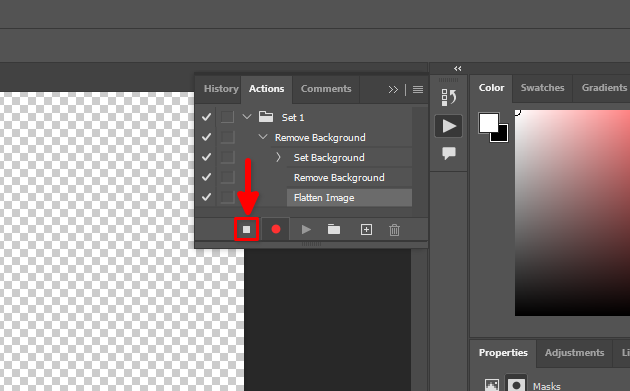
Nu kunt u het geopende bestand sluiten zonder de wijzigingen op te slaan en selecteert u File >> Scripts >> Image Processor…
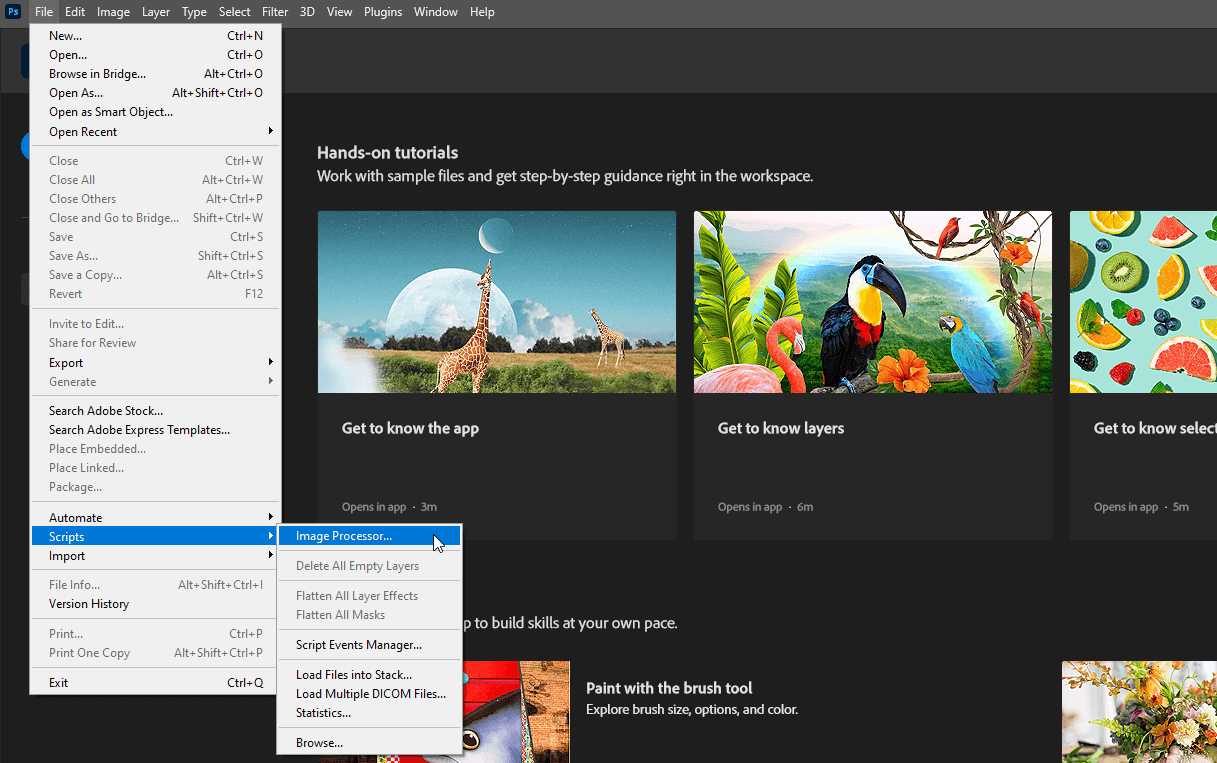
Selecteer de invoer- en uitvoermappen, kies de gemaakte Remove Background actie in stap 4 en klik op Run:
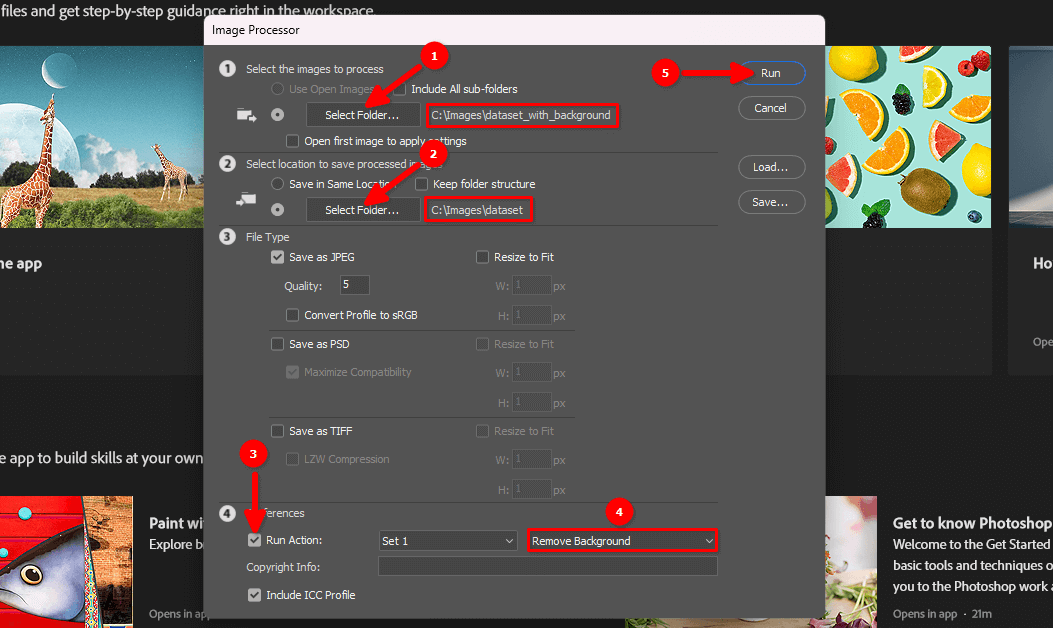
Wees geduldig. Adobe Photoshop zal elke afbeelding in de geselecteerde map openen, de opgenomen acties herhalen (laagvergrendeling uitschakelen, achtergrond verwijderen, afbeelding afvlakken) en opslaan in een andere geselecteerde map. Dit proces kan een paar minuten duren, afhankelijk van het aantal afbeeldingen.

Als het proces is voltooid, kun je naar de volgende stap gaan.
Uploaden naar server
Gebruik een van de volgende gidsen (aangepast aan het besturingssysteem van je pc) om de map dataset te uploaden naar de externe server. Plaats deze bijvoorbeeld in de homedirectory van de standaardgebruiker, /home/usergpu:
- Bestandsuitwisseling vanuit Linux
- Bestandsuitwisseling vanuit Windows
- Bestandsuitwisseling vanuit macOS
Pre-installatie
Werk bestaande systeempakketten bij:
sudo apt update && sudo apt -y upgradeInstalleer twee extra pakketten:
sudo apt install -y python3-tk python3.10-venvLaten we de CUDA® Toolkit versie 11.8 installeren. Laten we het specifieke pinbestand downloaden:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pinHet volgende commando plaatst het gedownloade bestand in de systeemdirectory, die wordt beheerd door de apt package manager:
sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600De volgende stap is het downloaden van de CUDA® repository:
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.debGa daarna verder met de pakketinstallatie met het standaard hulpprogramma dpkg:
sudo dpkg -i cuda-repo-ubuntu2204-11-8-local_11.8.0-520.61.05-1_amd64.debKopieer de GPG-sleutelring naar de systeemdirectory. Dit maakt het beschikbaar voor gebruik door besturingssysteemprogramma's, inclusief de apt package manager:
sudo cp /var/cuda-repo-ubuntu2204-11-8-local/cuda-*-keyring.gpg /usr/share/keyrings/Update systeem cache repositories:
sudo apt-get updateInstalleer de CUDA® toolkit met apt:
sudo apt-get -y install cudaVoeg CUDA® toe aan PATH. Open de bash shell config:
nano ~/.bashrcVoeg de volgende regels toe aan het einde van het bestand:
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}Sla het bestand op en start de server opnieuw op:
sudo shutdown -r nowTrainer installeren
Kopieer de repository van het Kohya project naar de server:
git clone https://github.com/bmaltais/kohya_ss.gitOpen de gedownloade map:
cd kohya_ssMaak het installatiescript uitvoerbaar:
chmod +x ./setup.shVoer het script uit:
./setup.shJe krijgt een waarschuwing van het versnellingshulpprogramma. Laten we het probleem oplossen. Activeer de virtuele omgeving van het project:
source venv/bin/activateInstalleer het ontbrekende pakket:
pip install scipyEn configureer het versnellingshulpprogramma handmatig:
accelerate configWees voorzichtig, want het activeren van een oneven aantal CPU's zal een fout veroorzaken. Als ik bijvoorbeeld 5 GPU's heb, kunnen er maar 4 worden gebruikt met deze software. Anders zal er een fout optreden wanneer het proces start. Je kunt de nieuwe configuratie van het hulpprogramma onmiddellijk controleren door een standaardtest aan te roepen:
accelerate testAls alles in orde is, krijg je een bericht als dit:
Test is a success! You are ready for your distributed training!
deactivateNu kun je de publieke server van de trainer starten met Gradio GUI en eenvoudige login/wachtwoord authenticatie (verander de gebruiker/wachtwoord in je eigen):
./gui.sh --share --username user --password passwordJe ontvangt twee strings:
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://.gradio.live
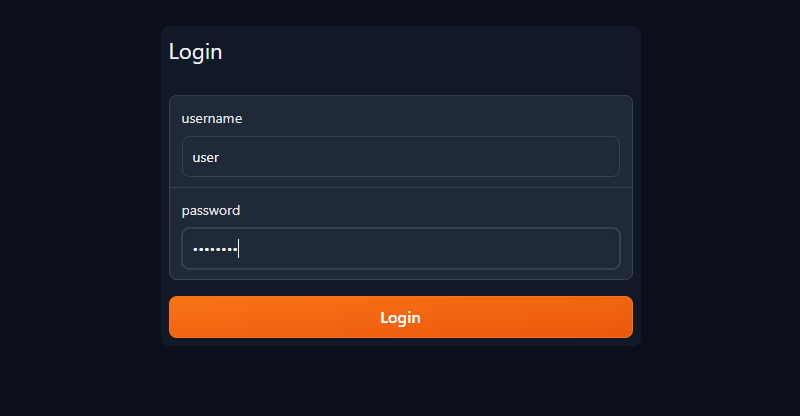
Open je webbrowser en voer de openbare URL in de adresbalk in. Typ je gebruikersnaam en wachtwoord in de daarvoor bestemde velden en klik op Aanmelden:
Bereid de dataset voor
Maak eerst een nieuwe map aan waarin je het getrainde LoRA-model opslaat:
mkdir /home/usergpu/myloramodelOpen de volgende tabbladen: Utilities >> Captioning >> BLIP captioning. Vul de openingen in zoals aangegeven in de afbeelding en klik op Caption images:
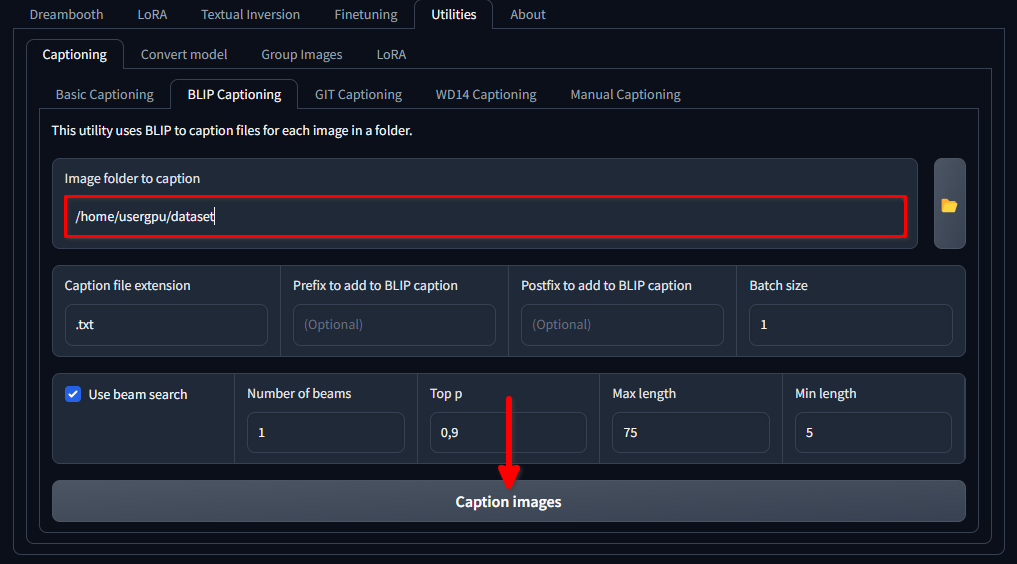
Trainer zal een specifiek neuraal netwerkmodel (1,6 Gb) downloaden en uitvoeren dat tekstaanwijzingen maakt voor elk afbeeldingsbestand in de geselecteerde map. Het wordt uitgevoerd op een enkele GPU en duurt ongeveer een minuut.
Ga naar LoRA >> Tools >> Dataset preparation >> Dreambooth/LoRA folder preparation, vul de gaten in en druk achtereenvolgens op Prepare training data en Copy info to Folders Tab:
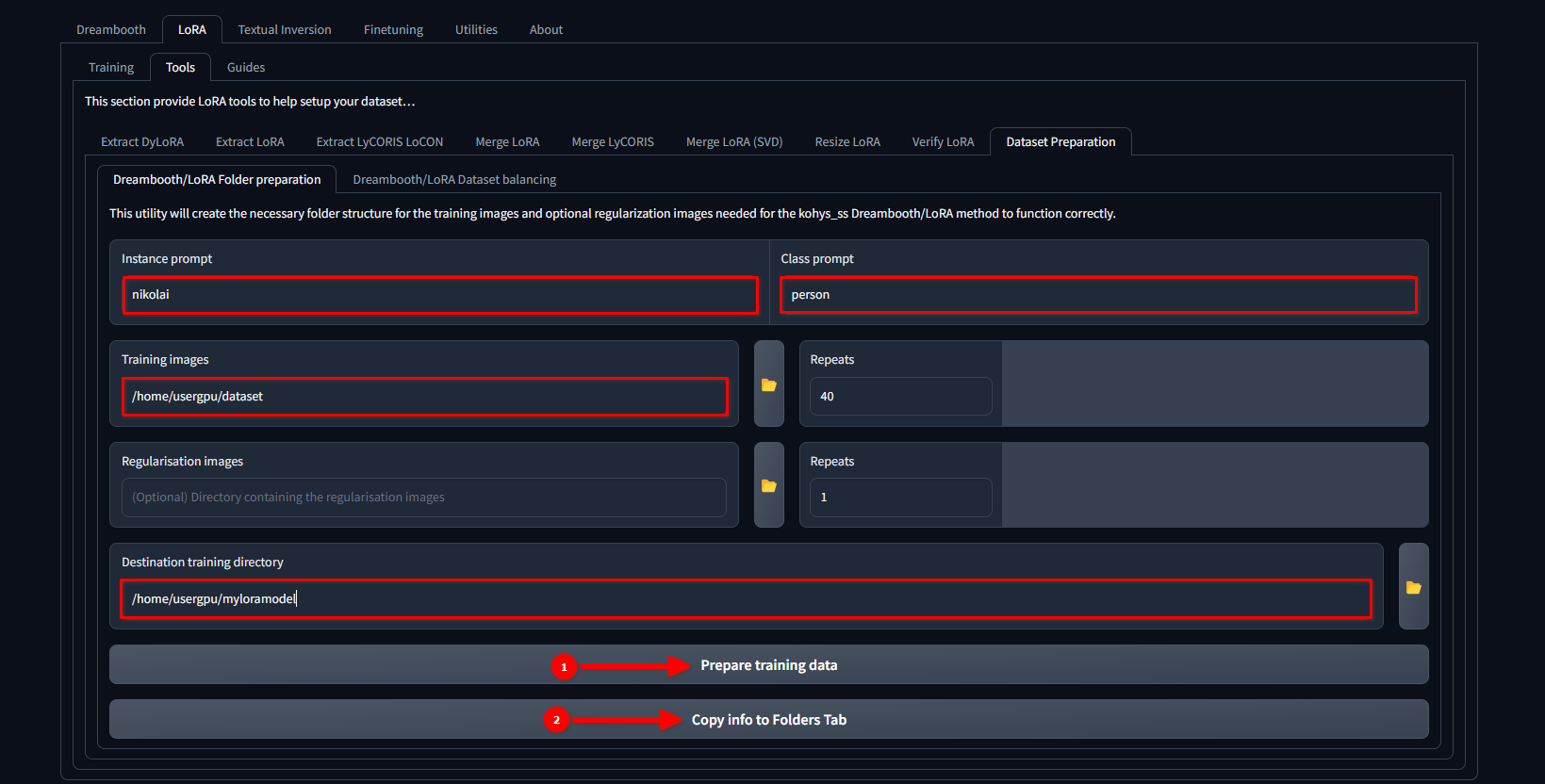
In dit voorbeeld gebruiken we de naam nikolai als een Instance prompt en "person" als een Class prompt. We stellen ook /home/usergpu/dataset in als een Training Images en /home/usergpu/myloramodel als een Destination training directory.
Ga opnieuw naar het tabblad LoRA >> Training >> Folders. Controleer of de Image folder, Output folder en Logging folder correct zijn ingevuld. Indien gewenst kunt u de Model output name wijzigen in uw eigen. Klik ten slotte op de knop Start training:
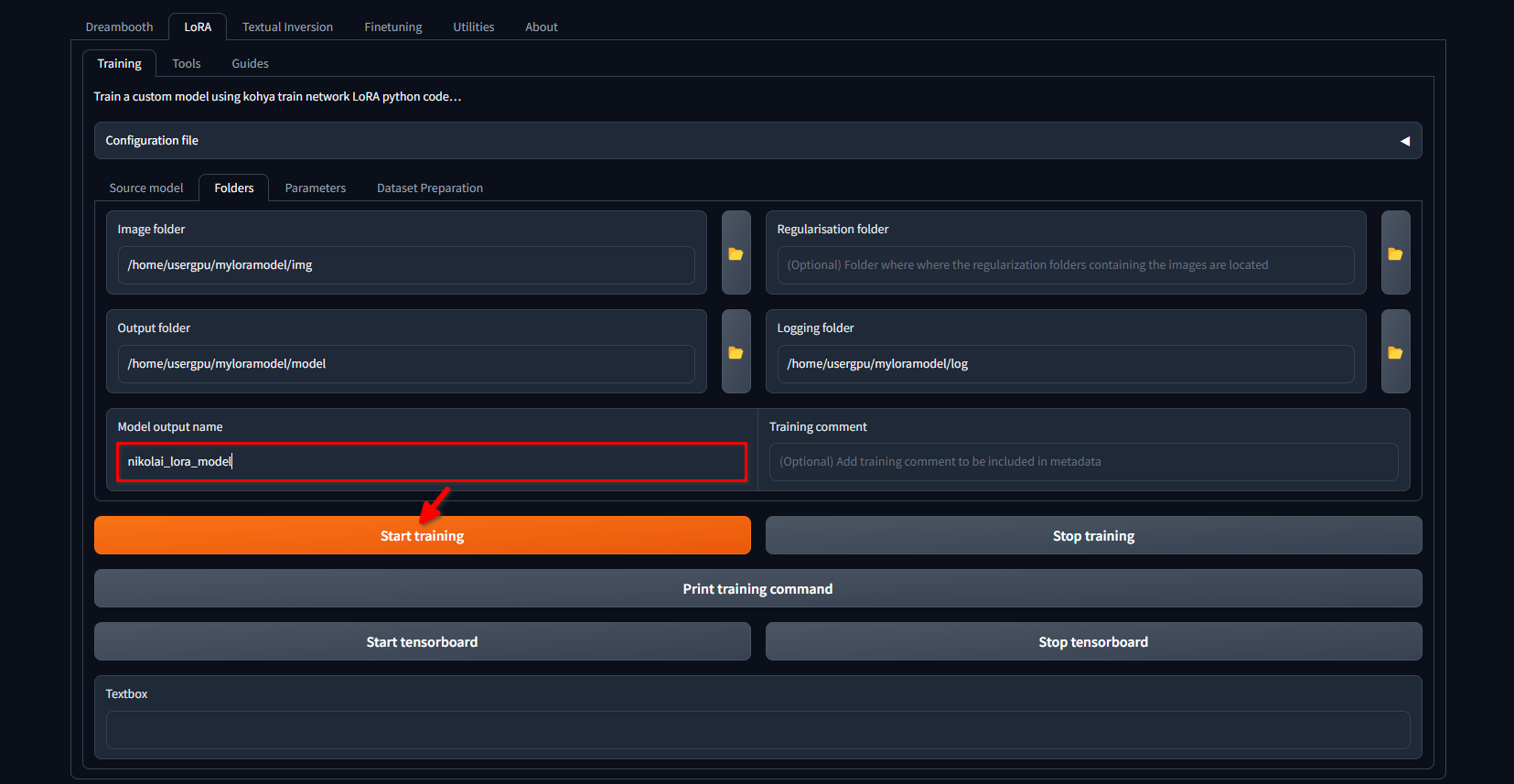
Het systeem zal beginnen met het downloaden van extra bestanden en modellen (~10 GB). Daarna begint het trainingsproces. Afhankelijk van de hoeveelheid afbeeldingen en de toegepaste instellingen kan dit enkele uren duren. Zodra de training is voltooid, kun je de map /home/usergpu/myloramodel downloaden naar je computer voor toekomstig gebruik.
Test je LoRA
We hebben enkele artikelen voorbereid over Stable Diffusion en zijn forks. Je kunt proberen om Easy Diffusion te installeren met onze gids Easy Diffusion UI. Nadat het systeem is geïnstalleerd en draait, kun je je LoRA-model in SafeTensors-formaat rechtstreeks uploaden naar /home/usergpu/easy-diffusion/models/lora
Werk de webpagina van Easy Diffusion bij en selecteer uw model in de vervolgkeuzelijst:
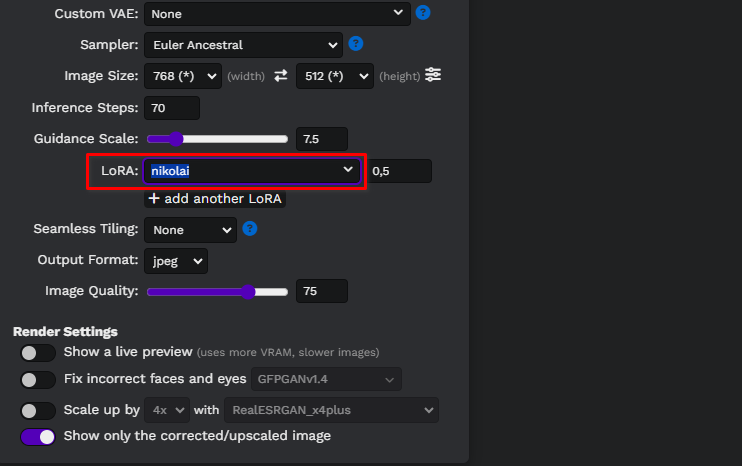
Laten we een eenvoudige prompt schrijven, portrait of <nikolai> wearing a cowboy hat, en onze eerste afbeeldingen genereren. Hier hebben we een aangepast Stable Diffusion-model gebruikt dat we hebben gedownload van civitai.com: Realistic Vision v6.0 B1:
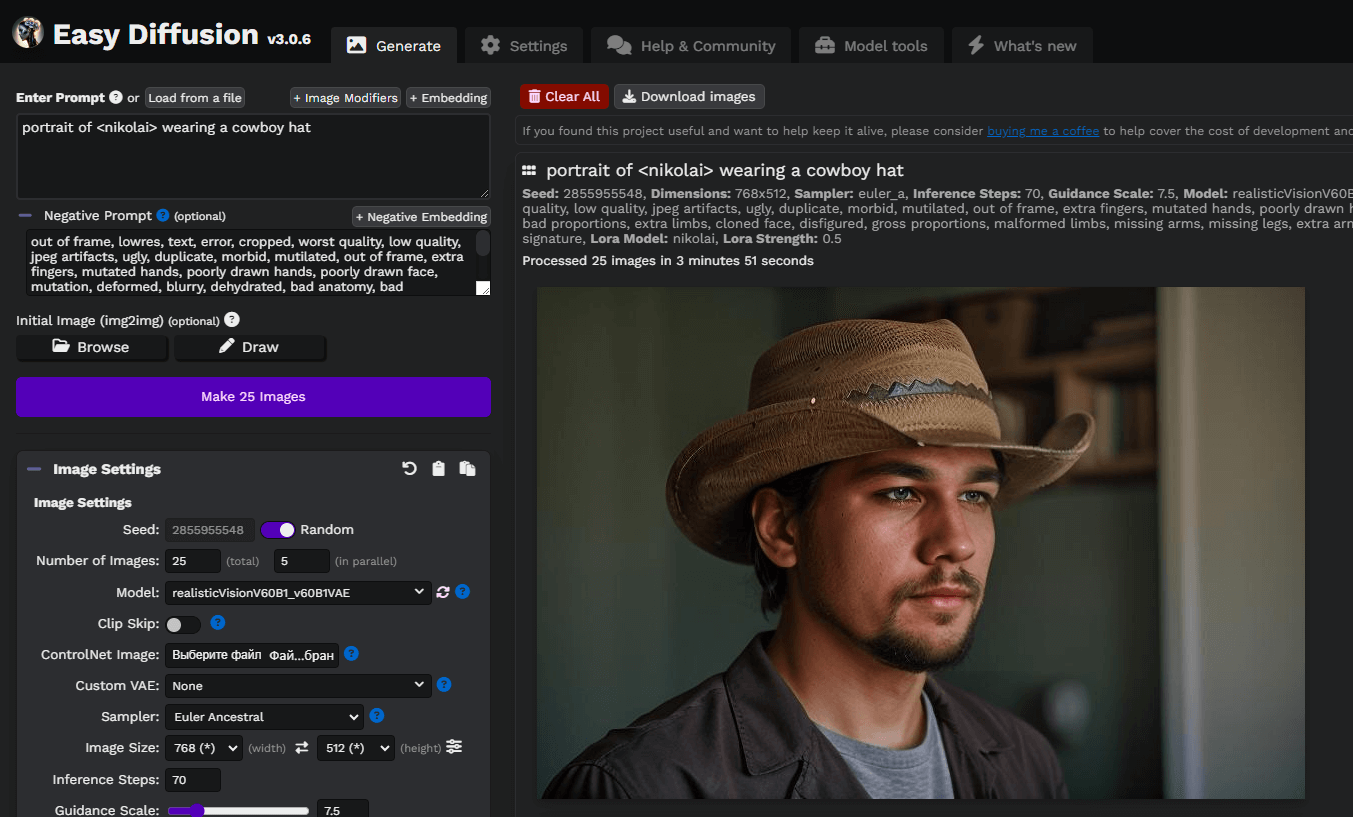
Je kunt experimenteren met aanwijzingen en modellen op basis van Stable Diffusion om betere resultaten te krijgen. Veel plezier!
Zie ook:
Bijgewerkt: 04.01.2026
Gepubliceerd: 21.01.2025




