





Low-code AI-app bouwer Langflow
Softwareontwikkeling heeft de laatste jaren een enorme ontwikkeling doorgemaakt. Moderne programmeurs hebben nu toegang tot honderden programmeertalen en frameworks. Naast de traditionele imperatieve en declaratieve benaderingen is er een nieuwe en opwindende methode voor het maken van toepassingen in opkomst. Deze innovatieve aanpak maakt gebruik van de kracht van neurale netwerken en biedt ontwikkelaars fantastische mogelijkheden.
Mensen zijn gewend geraakt aan AI-assistenten in IDE's die helpen met het automatisch aanvullen van code en moderne neurale netwerken die eenvoudig code genereren voor eenvoudige Python-spelletjes. Er zijn echter nieuwe hybride tools in opkomst die een revolutie teweeg kunnen brengen in het ontwikkellandschap. Eén zo'n hulpmiddel is Langflow.
Langflow dient meerdere doelen. Voor professionele ontwikkelaars biedt het betere controle over complexe systemen zoals neurale netwerken. Voor degenen die niet bekend zijn met programmeren, kunnen er eenvoudige maar praktische toepassingen mee worden gemaakt. Deze doelen worden op verschillende manieren bereikt, die we in meer detail zullen bespreken.
Neurale netwerken
Het concept van een neuraal netwerk kan worden vereenvoudigd voor gebruikers. Stel je een zwarte doos voor die invoergegevens en parameters ontvangt die het uiteindelijke resultaat beïnvloeden. Deze doos verwerkt de invoer met behulp van complexe algoritmen, vaak "magie" genoemd, en produceert uitvoergegevens die aan de gebruiker kunnen worden gepresenteerd.
De innerlijke werking van deze zwarte doos varieert op basis van het ontwerp en de trainingsgegevens van het neurale netwerk. Het is cruciaal om te begrijpen dat ontwikkelaars en gebruikers nooit 100% zekerheid in resultaten kunnen bereiken. In tegenstelling tot traditioneel programmeren waarbij 2 + 2 altijd gelijk is aan 4, kan een neuraal netwerk dit antwoord met 99% zekerheid geven, waarbij er altijd een foutmarge is.
De controle over het "denkproces" van een neuraal netwerk is indirect. We kunnen alleen bepaalde parameters aanpassen, zoals de "temperatuur". Deze parameter bepaalt hoe creatief of beperkt het neurale netwerk kan zijn in zijn benadering. Een lage temperatuurwaarde beperkt het netwerk tot een meer formele, gestructureerde benadering van taken en oplossingen. Omgekeerd geven hoge temperatuurwaarden het netwerk meer vrijheid, wat mogelijk leidt tot het vertrouwen op minder betrouwbare feiten of zelfs het creëren van fictieve informatie.
Dit voorbeeld illustreert hoe gebruikers de uiteindelijke output kunnen beïnvloeden. Voor traditionele programmering vormt deze onzekerheid een grote uitdaging - fouten kunnen onverwacht verschijnen en specifieke resultaten worden onvoorspelbaar. Deze onvoorspelbaarheid is echter vooral een probleem voor computers, niet voor mensen die zich kunnen aanpassen aan wisselende output en deze kunnen interpreteren.
Als de output van een neuraal netwerk bedoeld is voor een mens, is de specifieke formulering die gebruikt wordt om het te beschrijven over het algemeen minder belangrijk. Gegeven de context kunnen mensen verschillende resultaten correct interpreteren vanuit het perspectief van de machine. Hoewel begrippen als "positieve waarde", "bereikt resultaat" of "positieve beslissing" voor een mens ongeveer hetzelfde kunnen betekenen, zou traditionele programmering moeite hebben met deze flexibiliteit. Het zou rekening moeten houden met alle mogelijke antwoordvariaties, wat bijna onmogelijk is.
Aan de andere kant, als de verdere verwerking wordt uitbesteed aan een ander neuraal netwerk, kan het het verkregen resultaat correct begrijpen en verwerken. Op basis hiervan kan het dan zijn eigen conclusie vormen met een zekere mate van vertrouwen, zoals eerder vermeld.
Low-code
De meeste programmeertalen bevatten code. Programmeurs creëren de logica voor elk onderdeel van een toepassing in hun hoofd en beschrijven deze vervolgens met taalspecifieke uitdrukkingen. Dit proces vormt een algoritme: een duidelijke opeenvolging van acties die leiden tot een specifiek, vooraf bepaald resultaat. Het is een complexe taak die een aanzienlijke mentale inspanning en een grondig begrip van de mogelijkheden van de taal vereist.
Het is echter niet nodig om het wiel opnieuw uit te vinden. Veel problemen waar moderne ontwikkelaars mee te maken hebben, zijn al op verschillende manieren opgelost. Relevante stukjes code zijn vaak te vinden op StackOverflow. Modern programmeren kan worden vergeleken met het in elkaar zetten van een geheel uit onderdelen van verschillende bouwsets. Het Lego-systeem biedt een succesvol model, waarbij verschillende sets onderdelen gestandaardiseerd zijn om compatibiliteit te garanderen.
De low-code programmeermethode volgt een vergelijkbaar principe. Verschillende stukken code worden aangepast zodat ze naadloos in elkaar passen en worden aan ontwikkelaars gepresenteerd als kant-en-klare blokken. Elk blok kan data-ingangen en -uitgangen hebben. Documentatie specificeert de taak die elk bloktype oplost en het formaat waarin het gegevens accepteert of uitvoert.
Door deze blokken in een specifieke volgorde met elkaar te verbinden, kunnen ontwikkelaars het algoritme van een toepassing vormen en de operationele logica ervan duidelijk visualiseren. Misschien wel het bekendste voorbeeld van deze programmeermethode is de turtle graphics methode, die vaak gebruikt wordt in educatieve omgevingen om programmeerconcepten te introduceren en algoritmisch denken te ontwikkelen.
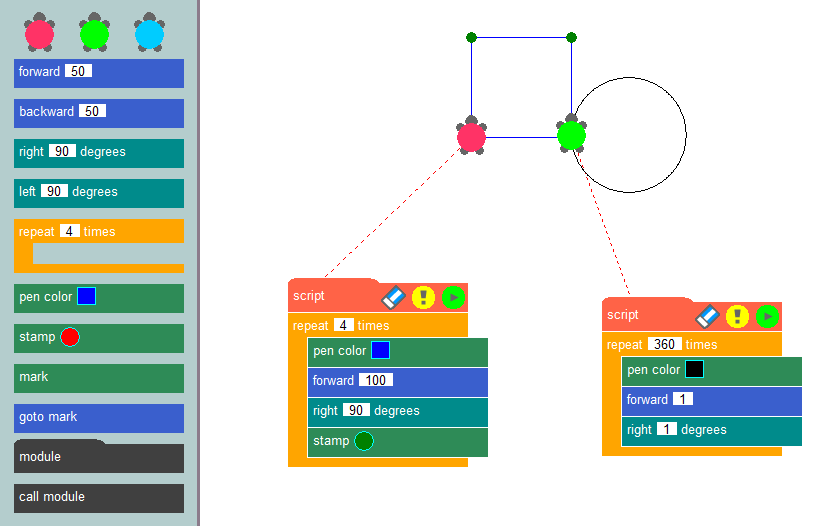
De essentie van deze methode is eenvoudig: afbeeldingen op het scherm tekenen met behulp van een virtuele schildpad die een spoor achterlaat terwijl hij over het canvas kruipt. Door gebruik te maken van kant-en-klare blokken, zoals het verplaatsen van een ingesteld aantal pixels, het draaien onder specifieke hoeken of het omhoog en omlaag bewegen van de pen, kunnen ontwikkelaars programma's maken die de gewenste afbeeldingen tekenen. Het maken van toepassingen met behulp van een low-code constructor is vergelijkbaar met schildpad afbeeldingen, maar het stelt gebruikers in staat om een breed scala aan problemen op te lossen, niet alleen het tekenen op een canvas.
Deze methode werd het best geïmplementeerd in IBM's Node-RED programmeertool. Het werd ontwikkeld als een universeel middel om de gezamenlijke werking van verschillende apparaten, online services en API's te garanderen. Het equivalent van code snippets waren nodes uit de standaard bibliotheek (palette).

De mogelijkheden van Node-RED kunnen worden uitgebreid door add-ons te installeren of aangepaste nodes te maken die specifieke gegevensacties uitvoeren. Ontwikkelaars plaatsen knooppunten uit het palet op het bureaublad en bouwen relaties tussen deze knooppunten. Dit proces creëert de logica van de toepassing, waarbij de visualisatie helpt om duidelijkheid te behouden.
De toevoeging van neurale netwerken aan dit concept levert een intrigerend systeem op. In plaats van gegevens te verwerken met specifieke wiskundige formules, kun je ze invoeren in een neuraal netwerk en de gewenste uitvoer specificeren. Hoewel de invoergegevens elke keer iets kunnen verschillen, blijven de resultaten geschikt voor interpretatie door mensen of andere neurale netwerken.
Retrieval Augmented Generation (RAG)
De nauwkeurigheid van gegevens in grote taalmodellen is een dringende zorg. Deze modellen vertrouwen uitsluitend op kennis die is opgedaan tijdens de training, die afhankelijk is van de relevantie van de gebruikte datasets. Bijgevolg kunnen grote taalmodellen onvoldoende relevante gegevens hebben, wat mogelijk leidt tot onjuiste resultaten.
Om dit probleem aan te pakken, zijn methoden voor het updaten van gegevens nodig. Door neurale netwerken context te laten halen uit aanvullende bronnen, zoals websites, kan de kwaliteit van antwoorden aanzienlijk worden verbeterd. Dit is precies hoe RAG (Retrieval-Augmented Generation) werkt. Aanvullende gegevens worden omgezet in vectorrepresentaties en opgeslagen in een database.
In de praktijk kunnen neurale netwerkmodellen verzoeken van gebruikers omzetten in vectorrepresentaties en deze vergelijken met de vectoren die zijn opgeslagen in de database. Als er vergelijkbare vectoren worden gevonden, worden de gegevens geëxtraheerd en gebruikt bij het vormen van een antwoord. Vectordatabases zijn snel genoeg om dit schema in realtime te ondersteunen.
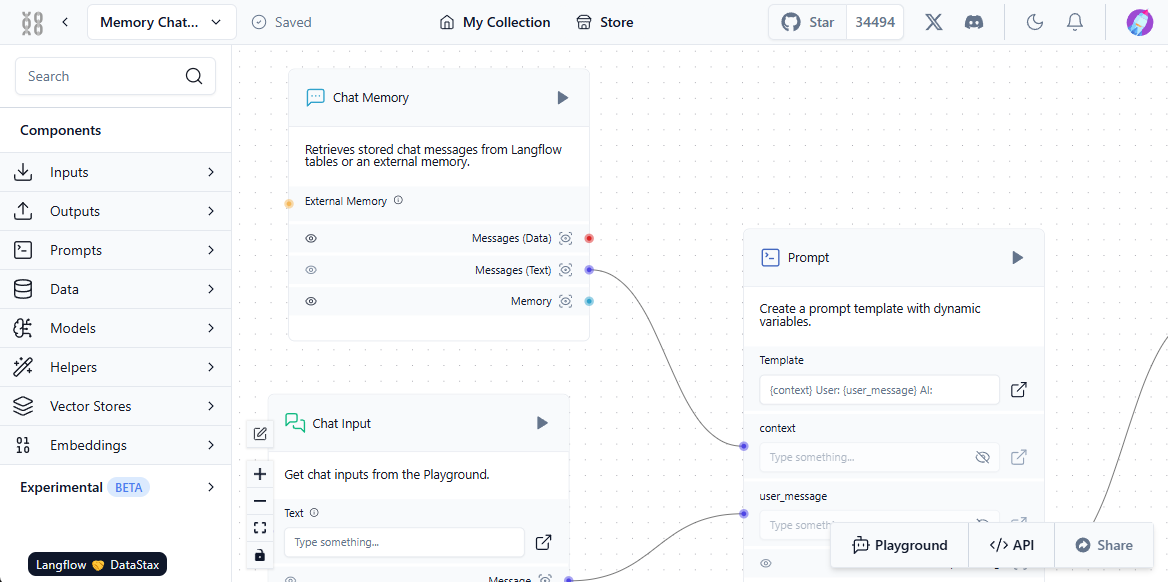
Om dit systeem goed te laten functioneren, moet er interactie zijn tussen de gebruiker, het neurale netwerkmodel, externe gegevensbronnen en de vectordatabase. Langflow vereenvoudigt deze opzet met zijn visuele component - gebruikers bouwen gewoon standaardblokken en "koppelen" ze, waardoor een pad voor gegevensstroom ontstaat.
De eerste stap is het vullen van de vector database met relevante bronnen. Dit kunnen bestanden zijn van een lokale computer of webpagina's van het internet. Hier is een eenvoudig voorbeeld van het laden van gegevens in de database:
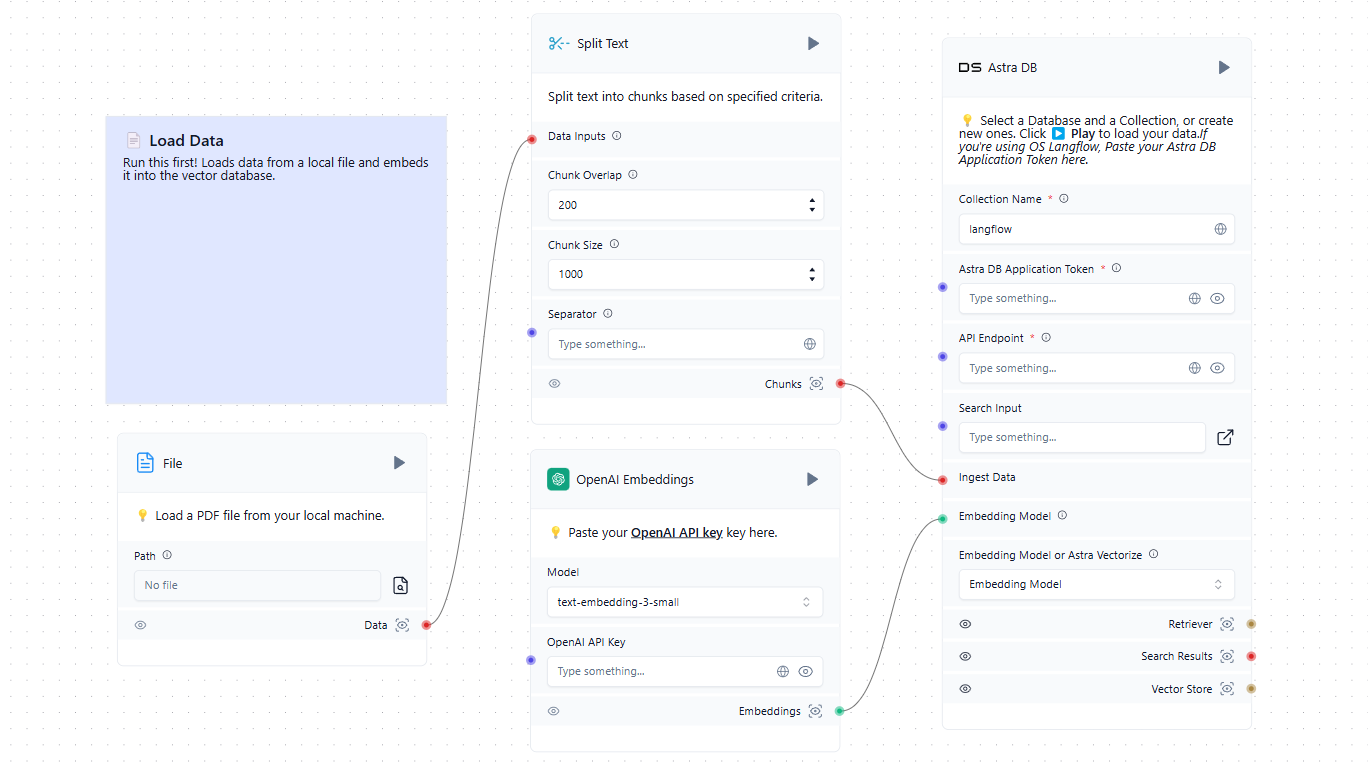
Nu we een vectordatabase hebben naast de getrainde LLM, kunnen we deze opnemen in het algemene schema. Wanneer een gebruiker een verzoek indient in de chat, wordt tegelijkertijd een prompt gevormd en de vectordatabase bevraagd. Als er vergelijkbare vectoren worden gevonden, worden de geëxtraheerde gegevens verwerkt en als context toegevoegd aan de gevormde prompt. Het systeem stuurt vervolgens een verzoek naar het neurale netwerk en stuurt het ontvangen antwoord naar de gebruiker in de chat.
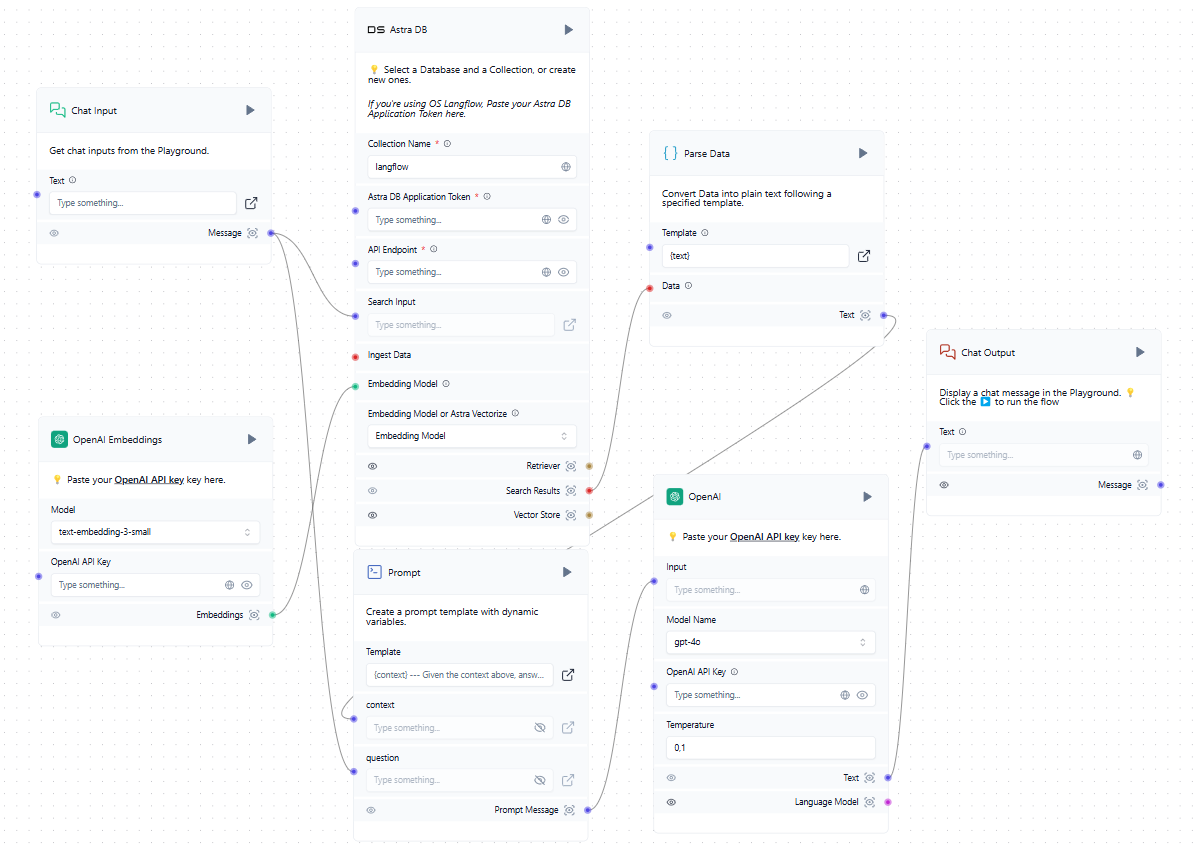
Hoewel in het voorbeeld clouddiensten zoals OpenAI en AstraDB worden genoemd, kun je elke compatibele dienst gebruiken, inclusief diensten die lokaal op de servers van LeaderGPU zijn geïnstalleerd. Als u de integratie die u nodig hebt niet kunt vinden in de lijst met beschikbare blokken, kunt u deze zelf schrijven of er een toevoegen die door iemand anders is gemaakt.
Snel aan de slag
Systeem voorbereiden
De eenvoudigste manier om Langflow te implementeren is in een Docker container. Om de server op te zetten, begin je met het installeren van Docker Engine. Werk vervolgens zowel de pakketcache als de pakketten bij naar de nieuwste versies:
sudo apt update && sudo apt -y upgradeInstalleer extra pakketten die Docker nodig heeft:
sudo apt -y install apt-transport-https ca-certificates curl software-properties-commonDownload de GPG-sleutel om de officiële Docker-repository toe te voegen:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpgVoeg de repository toe aan APT met de sleutel die je eerder hebt gedownload en geïnstalleerd:
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/nullVernieuw de pakketlijst:
sudo apt updateOm ervoor te zorgen dat Docker wordt geïnstalleerd vanuit de nieuw toegevoegde repository en niet vanuit de systeemrepository, kun je het volgende commando uitvoeren:
apt-cache policy docker-ceDocker Engine installeren:
sudo apt install docker-ceControleer of Docker met succes is geïnstalleerd en of de bijbehorende daemon draait en de status active (running) heeft:
sudo systemctl status docker● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset>
Active: active (running) since Mon 2024-11-18 08:26:35 UTC; 3h 27min ago
TriggeredBy: ● docker.socket
Docs: https://docs.docker.com
Main PID: 1842 (dockerd)
Tasks: 29
Memory: 1.8G
CPU: 3min 15.715s
CGroup: /system.slice/docker.service
Bouwen en uitvoeren
Alles is klaar om een Docker container met Langflow te bouwen en te draaien. Er is echter één voorbehoud: op het moment van schrijven van deze handleiding heeft de nieuwste versie (getagd v1.1.0) een fout en start niet op. Om dit probleem te voorkomen, gebruiken we de vorige versie, v1.0.19.post2, die direct na het downloaden vlekkeloos werkt.
De eenvoudigste aanpak is om de project repository te downloaden van GitHub:
git clone https://github.com/langflow-ai/langflowNavigeer naar de map met de voorbeeld deployment configuratie:
cd langflow/docker_exampleNu moet je twee dingen doen. Ten eerste, verander de release tag zodat een werkende versie (op het moment van schrijven van deze instructie) is gebouwd. Ten tweede, voeg eenvoudige authorisatie toe zodat niemand het systeem kan gebruiken zonder de login en het wachtwoord te kennen.
Open het configuratiebestand:
sudo nano docker-compose.ymlin plaats van de volgende regel:
image: langflowai/langflow:latestgeef de versie op in plaats van de tag latest:
image: langflowai/langflow:v1.0.19.post2Je moet ook drie variabelen toevoegen aan de sectie environment:
- LANGFLOW_AUTO_LOGIN=false
- LANGFLOW_SUPERUSER=admin
- LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordDe eerste variabele schakelt toegang tot de webinterface zonder autorisatie uit. De tweede voegt de gebruikersnaam toe die systeembeheerdersrechten krijgt. De derde voegt het bijbehorende wachtwoord toe.
Als u van plan bent om het bestand docker-compose.yml op te slaan in een versiebeheersysteem, schrijf het wachtwoord dan niet rechtstreeks in dit bestand. Maak in plaats daarvan een apart bestand met een .env extensie in dezelfde map en sla de variabele waarde daar op.
LANGFLOW_SUPERUSER_PASSWORD=your_secure_passwordIn het bestand docker-compose.yml kun je nu verwijzen naar een variabele in plaats van direct een wachtwoord op te geven:
LANGFLOW_SUPERUSER_PASSWORD=${LANGFLOW_SUPERUSER_PASSWORD}Om te voorkomen dat je per ongeluk het *.env bestand op GitHub blootgeeft, vergeet niet om het toe te voegen aan .gitignore. Dit zal je wachtwoord redelijk veilig houden van ongewenste toegang.
Nu hoeven we alleen nog maar onze container te bouwen en uit te voeren:
sudo docker compose upOpen de webpagina op http://[LeaderGPU_IP_address]:7860, en je ziet het autorisatieformulier:
Zodra je je login en wachtwoord hebt ingevoerd, geeft het systeem toegang tot de webinterface waar je je eigen applicaties kunt maken. Voor meer gedetailleerde begeleiding raden we aan om de officiële documentatie te raadplegen. Deze bevat details over verschillende omgevingsvariabelen die het mogelijk maken om het systeem eenvoudig aan te passen aan jouw behoeften.
Zie ook:
Bijgewerkt: 04.01.2026
Gepubliceerd: 22.01.2025




