





DeepSeek-R1: toekomst van LLM's

Hoewel generatieve neurale netwerken zich snel hebben ontwikkeld, is hun vooruitgang in de afgelopen jaren vrij stabiel gebleven. Dit veranderde met de komst van DeepSeek, een Chinees neuraal netwerk dat niet alleen de aandelenmarkt beïnvloedde maar ook de aandacht trok van ontwikkelaars en onderzoekers wereldwijd. In tegenstelling tot andere grote projecten werd de code van DeepSeek vrijgegeven onder de permissieve MIT-licentie. Deze stap naar open source oogstte lof van de gemeenschap, die gretig de mogelijkheden van het nieuwe model begon te verkennen.
Het meest indrukwekkende aspect was dat het trainen van dit nieuwe neurale netwerk naar verluidt 20 keer minder kostte dan concurrenten met een vergelijkbare kwaliteit. Het model had slechts 55 dagen en 5,6 miljoen dollar nodig om te trainen. Toen DeepSeek werd uitgebracht, veroorzaakte het een van de grootste dalingen op één dag in de geschiedenis van de Amerikaanse aandelenmarkt. Hoewel de markten zich uiteindelijk stabiliseerden, was de impact aanzienlijk.
In dit artikel wordt onderzocht hoe nauwkeurig de koppen in de media de werkelijkheid weerspiegelen en welke LeaderGPU-configuraties geschikt zijn om dit neurale netwerk zelf te installeren.
Architectonische kenmerken
DeepSeek heeft gekozen voor maximale optimalisatie, wat niet verwonderlijk is gezien de exportbeperkingen van China. Door deze beperkingen kan het land de meest geavanceerde GPU-modellen niet officieel gebruiken voor AI-ontwikkeling.
Het model maakt gebruik van MTP-technologie (Multi Token Prediction), die meerdere tokens voorspelt in een enkele inferentiestap in plaats van slechts één. Dit werkt door middel van parallelle token decodering in combinatie met speciale gemaskeerde lagen die autoregressiviteit behouden.
Testen met MTP hebben opmerkelijke resultaten laten zien, waarbij de generatiesnelheden 2-4 keer hoger zijn dan bij traditionele methoden. De uitstekende schaalbaarheid van de technologie maakt het waardevol voor huidige en toekomstige toepassingen voor de verwerking van natuurlijke taal.
Het Multi-Head Latent Attention (MLA) model heeft een verbeterd aandachtsmechanisme. Terwijl het model lange redeneerketens opbouwt, behoudt het in elke fase gerichte aandacht voor de context. Deze verbetering verbetert de verwerking van abstracte concepten en tekstafhankelijkheden.
De belangrijkste eigenschap van MLA is de mogelijkheid om dynamisch aandachtsgewichten aan te passen op verschillende abstractieniveaus. Bij het verwerken van complexe zoekopdrachten bekijkt MLA gegevens vanuit meerdere perspectieven: woordbetekenissen, zinsstructuren en de algehele context. Deze perspectieven vormen verschillende lagen die de uiteindelijke uitvoer beïnvloeden. Om helderheid te behouden, balanceert MLA zorgvuldig de impact van elke laag terwijl het zich blijft concentreren op de primaire taak.
De ontwikkelaars van DeepSeek hebben Mixture of Experts (MoE) technologie in het model verwerkt. Het bevat 256 voorgetrainde neurale netwerken van experts, elk gespecialiseerd voor verschillende taken. Het systeem activeert 8 van deze netwerken voor elke tokeninvoer, waardoor gegevens efficiënt worden verwerkt zonder dat de computerkosten toenemen.
In het volledige model met 671b parameters worden slechts 37b geactiveerd voor elk token. Het model selecteert op intelligente wijze de meest relevante parameters voor het verwerken van elk binnenkomend token. Deze efficiënte optimalisatie bespaart rekenkracht met behoud van hoge prestaties.
Een cruciaal kenmerk van elke neurale netwerkchatbot is de lengte van het contextvenster. Llama 2 heeft een contextlimiet van 4.096 tokens, GPT-3.5 verwerkt 16.284 tokens, terwijl GPT-4 en DeepSeek tot 128.000 tokens kunnen verwerken (ongeveer 100.000 woorden, gelijk aan 300 pagina's getypte tekst).
R - staat voor Redeneren
DeepSeek-R1 heeft een redeneermechanisme dat vergelijkbaar is met OpenAI o1, waardoor het complexe taken efficiënter en nauwkeuriger kan afhandelen. In plaats van direct antwoorden te geven, breidt het model de context uit door stapsgewijze redeneringen in kleine alinea's te genereren. Deze aanpak verbetert het vermogen van het neurale netwerk om complexe gegevensrelaties te identificeren, wat resulteert in uitgebreidere en nauwkeurigere antwoorden.
Wanneer DeepSeek wordt geconfronteerd met een complexe taak, gebruikt het zijn redeneermechanisme om het probleem op te splitsen in componenten en deze afzonderlijk te analyseren. Het model synthetiseert vervolgens deze bevindingen om een gebruikersreactie te genereren. Hoewel dit een ideale benadering lijkt voor neurale netwerken, brengt het aanzienlijke uitdagingen met zich mee.
Alle moderne LLM's delen een zorgwekkende eigenschap - kunstmatige hallucinaties. Wanneer het model een vraag krijgt die het niet kan beantwoorden, kan het, in plaats van zijn beperkingen te erkennen, fictieve antwoorden genereren die worden ondersteund door verzonnen feiten.
Toegepast op een redenerend neuraal netwerk kunnen deze hallucinaties het denkproces in gevaar brengen door conclusies te baseren op fictieve in plaats van feitelijke informatie. Dit kan leiden tot onjuiste conclusies - een uitdaging die onderzoekers en ontwikkelaars van neurale netwerken in de toekomst zullen moeten aangaan.
VRAM-verbruik
Laten we eens kijken hoe we DeepSeek R1 kunnen uitvoeren en testen op een speciale server, waarbij we ons concentreren op de vereisten voor GPU-videogeheugen.
| Model | VRAM (Mb) | Modelgrootte (Gb) |
|---|---|---|
| deepseek-r1:1.5b | 1,952 | 1.1 |
| deepseek-r1:7b | 5,604 | 4.7 |
| diepzeek-r1:8b | 6,482 | 4.9 |
| diepzeek-r1:14b | 10,880 | 9 |
| diepzeek-r1:32b | 21,758 | 20 |
| diepzeek-r1:70b | 39,284 | 43 |
| diepzeek-r1:671b | 470,091 | 404 |
De eerste drie opties (1.5b, 7b, 8b) zijn basismodellen die de meeste taken efficiënt aankunnen. Deze modellen draaien probleemloos op elke consumenten-GPU met 6-8 GB videogeheugen. De mid-tier versies (14b en 32b) zijn ideaal voor professionele taken, maar vereisen meer VRAM. De grootste modellen (70b en 671b) vereisen gespecialiseerde GPU's en worden voornamelijk gebruikt voor onderzoek en industriële toepassingen.
Server kiezen
Om u te helpen bij het kiezen van een server voor DeepSeek-inferentie, vindt u hier de ideale LeaderGPU-configuraties voor elke modelgroep:
1,5b / 7b / 8b / 14b / 32b / 70b
Voor deze groep is elke server met de volgende GPU-typen geschikt. De meeste LeaderGPU-servers zullen deze neurale netwerken zonder problemen uitvoeren. De prestaties zijn voornamelijk afhankelijk van het aantal CUDA® cores. Wij raden servers met meerdere GPU's aan, zoals:
671b
Nu het meest uitdagende geval: hoe voer je inferentie uit op een model met een basisgrootte van 404 GB? Dit betekent dat er ongeveer 470 GB videogeheugen nodig is. LeaderGPU biedt meerdere configuraties met de volgende GPU's die deze belasting aankunnen:
Beide configuraties verwerken de modelbelasting efficiënt en verdelen deze gelijkmatig over meerdere GPU's. Zo ziet een server met 8xH100 er bijvoorbeeld uit na het laden van het deepseek-r1:671b model:
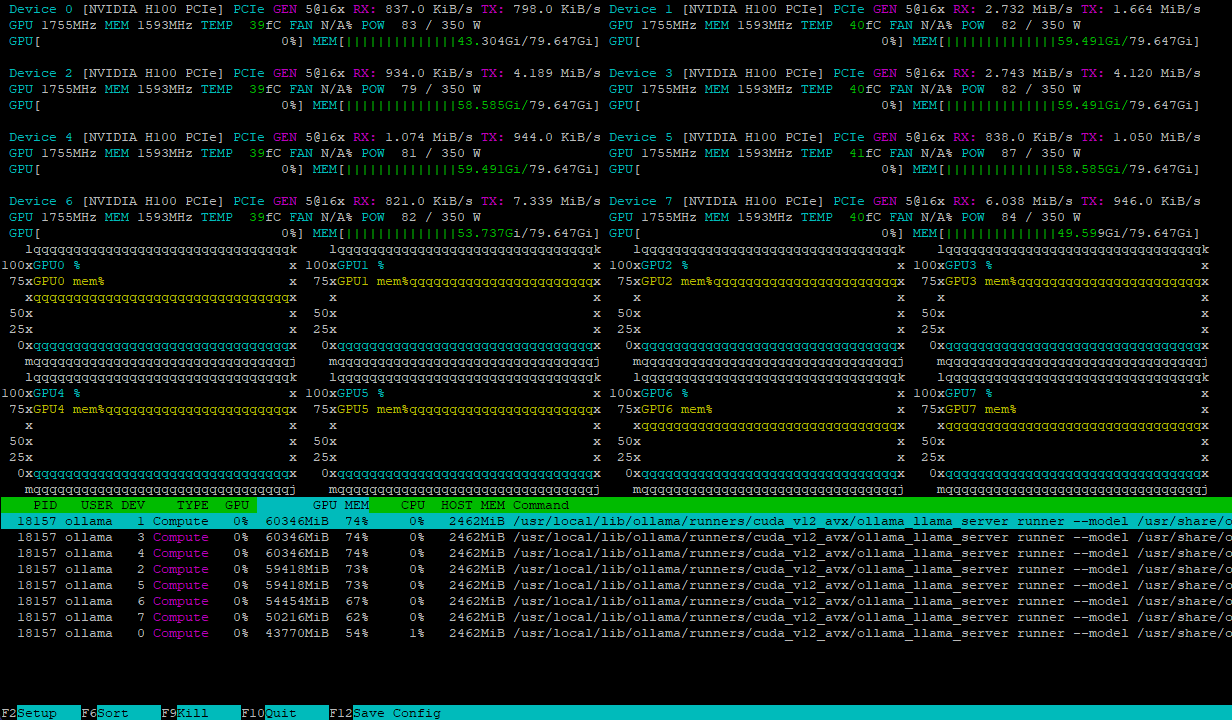
De rekenbelasting wordt dynamisch verdeeld over de GPU's, terwijl snelle NVLink® interconnecties knelpunten in de gegevensuitwisseling voorkomen, waardoor maximale prestaties worden gegarandeerd.
Conclusie
DeepSeek-R1 combineert veel innovatieve technologieën zoals Multi Token Prediction, Multi-Head Latent Attention en Mixture of Experts in één significant model. Deze open-source software laat zien dat LLM's efficiënter kunnen worden ontwikkeld met minder rekenkracht. Het model heeft verschillende versies van kleinere 1,5b tot enorme 671b die gespecialiseerde hardware vereisen met meerdere high-end GPU's die parallel werken.
Door een server van LeaderGPU te huren voor DeepSeek-R1-inferentie, krijgt u een breed scala aan configuraties, betrouwbaarheid en fouttolerantie. Ons technische ondersteuningsteam zal u helpen met eventuele problemen of vragen, terwijl de automatische installatie van het besturingssysteem de implementatietijd verkort.
Kies uw LeaderGPU server en ontdek de mogelijkheden die opengaan bij het gebruik van moderne neurale netwerkmodellen. Als u vragen heeft, aarzel dan niet om ze te stellen in onze chat of e-mail.
Bijgewerkt: 04.01.2026
Gepubliceerd: 19.02.2025




