





Wat is kennisdistillatie
Grote taalmodellen (LLM's) zijn door hun unieke mogelijkheden een integraal onderdeel van ons leven geworden. Ze begrijpen context en genereren op basis daarvan samenhangende, uitgebreide teksten. Ze kunnen elke taal verwerken en erop reageren, rekening houdend met de culturele nuances van elke taal.
LLM's blinken uit in complexe problemen oplossen, programmeren, gesprekken voeren en nog veel meer. Deze veelzijdigheid komt voort uit het verwerken van enorme hoeveelheden trainingsgegevens, vandaar de term "groot". Deze modellen kunnen tientallen of honderden miljarden parameters bevatten, waardoor ze veel resources vereisen voor dagelijks gebruik.
Training is het meest veeleisende proces. Neurale netwerkmodellen leren door enorme datasets te verwerken en hun interne "gewichten" aan te passen om stabiele verbindingen tussen neuronen te vormen. Deze verbindingen slaan kennis op die het getrainde neurale netwerk later kan gebruiken op eindapparaten.
De meeste eindapparaten beschikken echter niet over de nodige rekenkracht om deze modellen uit te voeren. Voor het uitvoeren van de volledige versie van Llama 2 (70B parameters) is bijvoorbeeld een GPU met 48 GB videogeheugen nodig, hardware die maar weinig gebruikers thuis hebben, laat staan op mobiele apparaten.
Daarom werken de meeste moderne neurale netwerken in een cloud-infrastructuur in plaats van op draagbare apparaten, die via API's toegang hebben tot deze netwerken. Toch boeken fabrikanten op twee manieren vooruitgang: ze rusten apparaten uit met gespecialiseerde rekeneenheden zoals NPU's en ontwikkelen methoden om de prestaties van compacte neurale netwerkmodellen te verbeteren.
De omvang verkleinen
Het teveel wegsnijden
Quantisatie is de eerste en meest effectieve methode om de grootte van het neurale netwerk te verkleinen. Gewichten van neurale netwerken gebruiken meestal 32-bits drijvendekomma getallen, maar we kunnen ze verkleinen door dit formaat te wijzigen. Het gebruik van 8-bits waarden (of zelfs binaire waarden in sommige gevallen) kan de grootte van het netwerk vertienvoudigen, hoewel dit de nauwkeurigheid van de antwoorden aanzienlijk vermindert.
Pruning is een andere aanpak, waarbij onbelangrijke verbindingen in het neurale netwerk worden verwijderd. Dit proces werkt zowel tijdens de training als bij voltooide netwerken. Naast alleen verbindingen kan snoeien ook neuronen of hele lagen verwijderen. Deze vermindering in parameters en verbindingen leidt tot een lager geheugengebruik.
Matrix- of tensordecompositie is de derde veelgebruikte techniek om de grootte te reduceren. Het opsplitsen van een grote matrix in een product van drie kleinere matrices vermindert het totaal aantal parameters met behoud van kwaliteit. Dit kan de grootte van het netwerk tientallen keren verkleinen. Tensor decompositie biedt nog betere resultaten, maar vereist meer hyperparameters.
Hoewel deze methoden effectief de grootte verkleinen, hebben ze allemaal te maken met kwaliteitsverlies. Grote gecomprimeerde modellen presteren beter dan hun kleinere, niet-gecomprimeerde tegenhangers, maar bij elke compressie bestaat het risico dat de antwoordnauwkeurigheid afneemt. Kennisdistillatie is een interessante poging om een balans te vinden tussen kwaliteit en grootte.
Laten we het samen proberen
Kennisdistillatie kan het best worden uitgelegd aan de hand van de analogie van een leerling en een leraar. Terwijl studenten leren, geven docenten les en werken ze hun bestaande kennis voortdurend bij. Wanneer beiden op nieuwe kennis stuiten, heeft de leraar een voordeel, hij kan putten uit zijn brede kennis van andere gebieden, terwijl de student deze basis nog niet heeft.
Dit principe is van toepassing op neurale netwerken. Wanneer twee neurale netwerken van hetzelfde type maar van verschillende grootte op identieke gegevens worden getraind, presteert het grotere netwerk meestal beter. Zijn grotere capaciteit voor "kennis" maakt nauwkeurigere reacties mogelijk dan zijn kleinere tegenhanger. Dit roept een interessante mogelijkheid op: waarom trainen we het kleinere netwerk niet niet alleen op de dataset, maar ook op de nauwkeurigere uitkomsten van het grotere netwerk?
Dit proces is kennisdistillatie: een vorm van supervised learning waarbij een kleiner model leert om de voorspellingen van een groter model te repliceren. Hoewel deze techniek helpt om het kwaliteitsverlies door het verkleinen van het neurale netwerk te compenseren, vereist het wel extra rekenkracht en trainingstijd.
Software en logica
Nu de theoretische basis duidelijk is, kunnen we het proces vanuit een technisch perspectief bekijken. We beginnen met softwaretools die je door de training en kennisdistillatie kunnen leiden.
Python, samen met de TorchTune bibliotheek van het PyTorch ecosysteem, biedt de eenvoudigste aanpak voor het bestuderen en fine-tunen van grote taalmodellen. Dit is hoe de toepassing werkt:
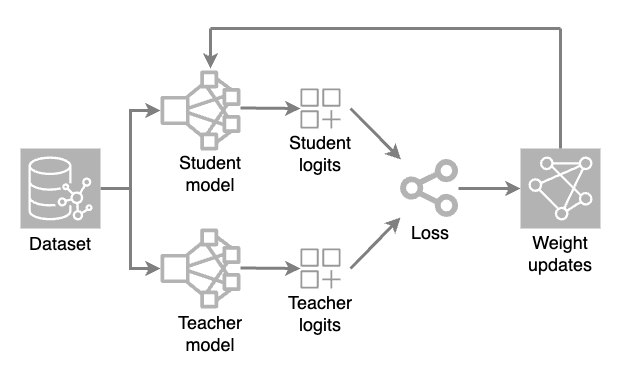
Er worden twee modellen geladen: een volledig model (leraar) en een gereduceerd model (leerling). Tijdens elke trainings iteratie genereert het teacher model hoge temperatuur voorspellingen terwijl het student model de dataset verwerkt om zijn eigen voorspellingen te doen.
De ruwe uitvoerwaarden (logits) van beide modellen worden geëvalueerd met behulp van een verliesfunctie (een numerieke maat voor hoeveel een voorspelling afwijkt van de juiste waarde). Gewichtsaanpassingen worden dan toegepast op het leerlingmodel door middel van backpropagatie. Hierdoor kan het kleinere model leren en de voorspellingen van het leraarmodel repliceren.
Het primaire configuratiebestand in de applicatiecode wordt een recept genoemd. In dit bestand worden alle distillatieparameters en instellingen opgeslagen, waardoor experimenten reproduceerbaar worden en onderzoekers kunnen bijhouden hoe verschillende parameters het uiteindelijke resultaat beïnvloeden.
Bij het selecteren van parameterwaarden en iteratietellingen is het behouden van evenwicht cruciaal. Een model dat te veel gedistilleerd heeft, kan zijn vermogen verliezen om subtiele details en context te herkennen, waardoor het terugvalt op standaard reacties. Hoewel een perfecte balans bijna onmogelijk te bereiken is, kan het zorgvuldig bewaken van het destillatieproces de voorspellingskwaliteit van zelfs bescheiden neurale netwerkmodellen aanzienlijk verbeteren.
Het is ook de moeite waard om aandacht te besteden aan monitoring tijdens het trainingsproces. Dit zal helpen om problemen op tijd te identificeren en onmiddellijk te corrigeren. Hiervoor kun je de tool TensorBoard gebruiken. Het integreert naadloos in PyTorch-projecten en stelt je in staat om veel metrieken visueel te evalueren, zoals nauwkeurigheid en verliezen. Bovendien kun je er een modeldiagram mee maken en het geheugengebruik en de uitvoeringstijd van bewerkingen mee bijhouden.
Conclusie
Kennisdistillatie is een effectieve methode voor het optimaliseren van neurale netwerken om compacte modellen te verbeteren. Het werkt het beste wanneer het balanceren van prestaties met antwoordkwaliteit essentieel is.
Hoewel kennisdestillatie zorgvuldig toezicht vereist, kunnen de resultaten opmerkelijk zijn. Modellen worden veel kleiner met behoud van voorspellingskwaliteit en ze presteren beter met minder rekenkracht.
Als kennisdestillatie goed wordt gepland met de juiste parameters, is het een belangrijk hulpmiddel om compacte neurale netwerken te maken zonder aan kwaliteit in te boeten.
Zie ook:
Bijgewerkt: 04.01.2026
Gepubliceerd: 23.01.2025




