





Triton™ Inference Server

Zakelijke eisen kunnen verschillen, maar ze hebben allemaal één kernprincipe gemeen: systemen moeten snel werken en de hoogst mogelijke kwaliteit leveren. Als het gaat om neurale netwerkinferentie, is efficiënt gebruik van computermiddelen van cruciaal belang. Onderbenutting of inactiviteit van GPU's leidt direct tot financiële verliezen.
Neem een marktplaats als voorbeeld. Deze platformen hosten talloze producten, elk met meerdere attributen: tekstbeschrijvingen, technische specificaties, categorieën en multimedia-inhoud zoals foto's en video's. Alle inhoud moet gemodereerd worden om eerlijk te blijven. Alle inhoud moet worden gemodereerd om eerlijke voorwaarden te handhaven voor verkopers en om te voorkomen dat verboden goederen of illegale inhoud op het platform verschijnen.
Handmatige moderatie is mogelijk, maar het is traag en inefficiënt. In de huidige competitieve omgeving moeten verkopers hun productaanbod snel uitbreiden: hoe sneller items op de marktplaats verschijnen, hoe groter de kans dat ze ontdekt en gekocht worden. Handmatige moderatie is ook duur en gevoelig voor menselijke fouten, waardoor mogelijk ongepaste inhoud wordt doorgelaten.
Automatische moderatie met behulp van speciaal getrainde neurale netwerken biedt een oplossing. Deze aanpak heeft meerdere voordelen: het vermindert de kosten voor moderatie aanzienlijk en verbetert tegelijkertijd de kwaliteit. Neurale netwerken verwerken inhoud veel sneller dan mensen, waardoor verkopers de moderatiefase sneller kunnen doorlopen, vooral bij grote productvolumes.
De aanpak heeft ook zijn uitdagingen. Het implementeren van geautomatiseerde moderatie vereist het ontwikkelen en trainen van neurale netwerkmodellen, wat zowel geschoold personeel als aanzienlijke computerbronnen vereist. De voordelen worden echter snel duidelijk na de eerste implementatie. Het toevoegen van geautomatiseerde modelimplementatie kan de lopende werkzaamheden aanzienlijk stroomlijnen.
Inferentie
Stel dat we de procedures voor machinaal leren hebben bedacht. De volgende stap is bepalen hoe modelinferentie op een gehuurde server moet worden uitgevoerd. Voor een enkel model kies je meestal een tool die goed werkt met het specifieke framework waarop het gebouwd is. Als je echter te maken hebt met meerdere modellen die in verschillende frameworks zijn gemaakt, heb je twee opties.
Je kunt alle modellen converteren naar één formaat of een tool kiezen die meerdere frameworks ondersteunt. Triton™ Inference Server past perfect bij de tweede benadering. Het ondersteunt de volgende backends:
- TensorRT™
- TensorRT-LLM
- vLLM
- Python
- PyTorch (LibTorch)
- ONNX-runtime
- Tensorflow
- FIL
- DALI
Bovendien kun je elke toepassing als backend gebruiken. Als je bijvoorbeeld nabewerking nodig hebt met een C/C++ toepassing, kun je die naadloos integreren.
Schalen
Triton™ Inference Server beheert computermiddelen efficiënt op een enkele server door meerdere modellen tegelijkertijd uit te voeren en de werklast over GPU's te verdelen.
Installatie gebeurt via een Docker-container. DevOps-technici kunnen de GPU-toewijzing bij het opstarten regelen en ervoor kiezen om alle GPU's te gebruiken of hun aantal te beperken. Hoewel de software niet direct horizontale schaalbaarheid behandelt, kun je hiervoor traditionele loadbalancers zoals HAproxy gebruiken of applicaties in een Kubernetes-cluster implementeren.
Het systeem voorbereiden
Om Triton™ in te stellen op een LeaderGPU server met Ubuntu 22.04, moet je eerst het systeem updaten met dit commando:
sudo apt update && sudo apt -y upgradeInstalleer eerst de NVIDIA® drivers met behulp van het autoinstaller script:
sudo ubuntu-drivers autoinstallStart de server opnieuw op om de wijzigingen toe te passen:
sudo shutdown -r nowZodra de server weer online is, installeer je Docker met het volgende installatiescript:
curl -sSL https://get.docker.com/ | shAangezien Docker standaard geen GPU's kan doorgeven aan containers, heb je de NVIDIA® Container Toolkit nodig. Voeg de Nvidia-repository toe door de GPG-sleutel ervan te downloaden en te registreren:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listUpdate de packages cache en installeer de toolkit:
sudo apt update && sudo apt -y install nvidia-container-toolkitStart Docker opnieuw op om de nieuwe mogelijkheden in te schakelen:
sudo systemctl restart dockerHet besturingssysteem is nu klaar voor gebruik.
Triton™ inferentieserver installeren
Laten we de projectrepository downloaden:
git clone https://github.com/triton-inference-server/serverDeze repository bevat vooraf geconfigureerde neurale netwerkvoorbeelden en een downloadscript voor modellen. Navigeer naar de map examples:
cd server/docs/examplesDownload de modellen door het volgende script uit te voeren, dat ze opslaat op ~/server/docs/examples/model_repository:
./fetch_models.shDe architectuur van Triton™ Inference Server vereist dat modellen afzonderlijk worden opgeslagen. Je kunt ze lokaal opslaan in een servermap of op netwerkopslag. Bij het opstarten van de server moet je deze map koppelen aan de container op het koppelpunt /models. Dit dient als opslagplaats voor alle modelversies.
Start de container met dit commando
sudo docker run --gpus=all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ~/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:25.01-py3 tritonserver --model-repository=/modelsHier is wat elke parameter doet:
- --gpus=all specificeert dat alle beschikbare GPU's worden gebruikt in de server;
- --rm vernietigt de container nadat het proces is voltooid of gestopt;
- -p8000:8000 stuurt poort 8000 door om HTTP-verzoeken te ontvangen;
- -p8001:8001 stuurt poort 8001 door om gRPC verzoeken te ontvangen;
- -p8002:8002 stuurt poort 8002 door om metriek op te vragen;
- -v ~/server/docs/examples/model_repository:/models stuurt de directory met modellen door;
- nvcr.io/nvidia/tritonserver:25.01-py3 adres van de container uit de NGC™ catalogus;
- tritonserver --model-repository=/models start de Triton™ Inference Server met de locatie van de models repository op /models.
De uitvoer van het commando toont alle beschikbare modellen in de repository, elk klaar om verzoeken te accepteren:
+----------------------+---------+--------+ | Model | Version | Status | +----------------------+---------+--------+ | densenet_onnx | 1 | READY | | inception_graphdef | 1 | READY | | simple | 1 | READY | | simple_dyna_sequence | 1 | READY | | simple_identity | 1 | READY | | simple_int8 | 1 | READY | | simple_sequence | 1 | READY | | simple_string | 1 | READY | +----------------------+---------+--------+
De drie diensten zijn succesvol gestart op poorten 8000, 8001 en 8002:
I0217 08:00:34.930188 1 grpc_server.cc:2466] Started GRPCInferenceService at 0.0.0.0:8001 I0217 08:00:34.930393 1 http_server.cc:4636] Started HTTPService at 0.0.0.0:8000 I0217 08:00:34.972340 1 http_server.cc:320] Started Metrics Service at 0.0.0.0:8002
Met het hulpprogramma nvtop kunnen we controleren of alle GPU's klaar zijn om de belasting te accepteren:
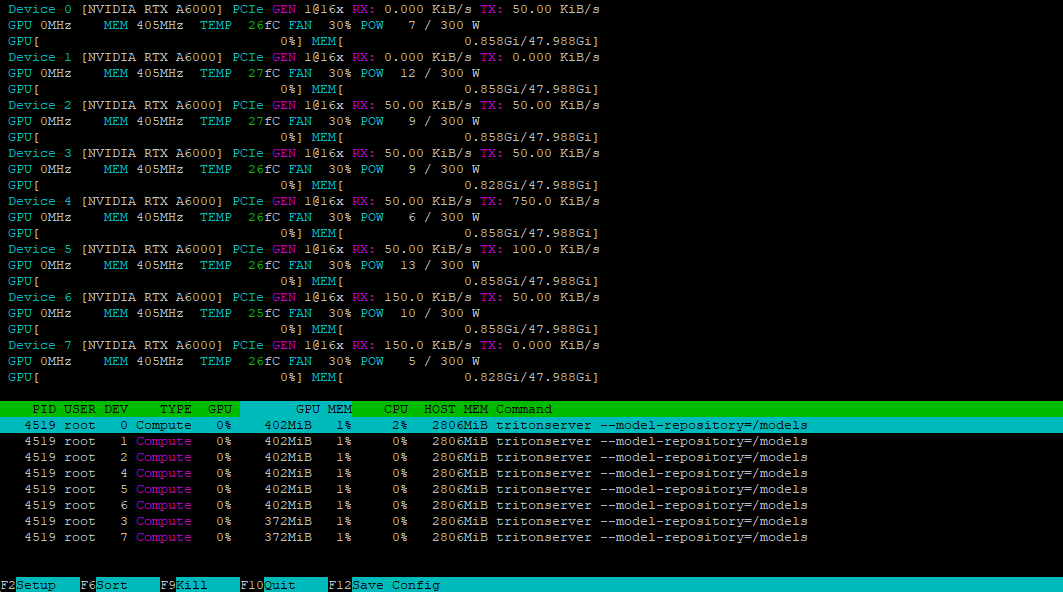
De client installeren
Om toegang te krijgen tot onze server, moeten we een geschikt verzoek genereren met de client die bij de SDK zit. We kunnen deze SDK downloaden als een Docker-container:
sudo docker pull nvcr.io/nvidia/tritonserver:25.01-py3-sdkStart de container in interactieve modus om toegang te krijgen tot de console:
sudo docker run -it --gpus=all --rm --net=host nvcr.io/nvidia/tritonserver:25.01-py3-sdkLaten we dit eens testen met het DenseNet-model in ONNX-indeling, met behulp van de INCEPTION-methode voor het voorbewerken en analyseren van afbeeldingen mug.jpg:
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpgDe client neemt contact op met de server, die een batch aanmaakt en deze verwerkt met behulp van de beschikbare GPU's van de container. Hier is de uitvoer:
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.349562 (504) = COFFEE MUG
13.227461 (968) = CUP
10.424891 (505) = COFFEEPOTDe repository voorbereiden
Om Triton™ modellen correct te laten beheren, moet je het archief op een specifieke manier voorbereiden. Dit is de mapstructuur:
model_repository/
└── your_model/
├── config.pbtxt
└── 1/
└── model.*
Elk model heeft zijn eigen map nodig met daarin een config.pbtxt configuratiebestand met zijn beschrijving. Hier is een voorbeeld:
name: "Test"
platform: "pytorch_libtorch"
max_batch_size: 8
input [
{
name: "INPUT_0"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
output [
{
name: "OUTPUT_0"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]In dit voorbeeld zal een model met de naam Test draaien op de PyTorch backend. De parameter max_batch_size stelt het maximum aantal items in dat gelijktijdig kan worden verwerkt, zodat de belasting van de bronnen efficiënt kan worden verdeeld. Door deze waarde op nul te zetten, wordt batching uitgeschakeld, waardoor het model aanvragen sequentieel verwerkt.
Het model accepteert één invoer en produceert één uitvoer, beide gebruikmakend van het FP32 nummertype. De parameters moeten precies overeenkomen met de vereisten van het model. Voor beeldverwerking is een typische maatspecificatie dims: [ 3, 224, 224 ], waarbij:
- 3 - aantal kleurkanalen (RGB);
- 224 - afbeeldingshoogte in pixels;
- 224 - beeldbreedte in pixels.
De uitvoer dims: [ 1000 ] is een eendimensionale vector van 1000 elementen, die geschikt is voor beeldclassificatietaken. Raadpleeg de documentatie van je model om de juiste dimensionaliteit te bepalen. Als het configuratiebestand onvolledig is, probeert Triton™ ontbrekende parameters automatisch te genereren.
Een aangepast model starten
Laten we de inferentie starten van het gedistilleerde DeepSeek-R1 model dat we eerder bespraken. Eerst maken we de noodzakelijke mappenstructuur aan:
mkdir ~/model_repository && mkdir ~/model_repository/deepseek && mkdir ~/model_repository/deepseek/1Navigeer naar de modeldirectory:
cd ~/model_repository/deepseekMaak een configuratiebestand config.pbtxt:
nano config.pbtxtPlak het volgende:
# Copyright 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions
# are met:
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
# * Neither the name of NVIDIA CORPORATION nor the names of its
# contributors may be used to endorse or promote products derived
# from this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND ANY
# EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
# PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR
# CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
# EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
# PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
# PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY
# OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
# Note: You do not need to change any fields in this configuration.
backend: "vllm"
# The usage of device is deferred to the vLLM engine
instance_group [
{
count: 1
kind: KIND_MODEL
}
]Sla het bestand op door te drukken op Ctrl + O, daarna de editor met Ctrl + X. Navigeer naar de directory 1:
cd 1Maak een modelconfiguratiebestand model.json met de volgende parameters:
{
"model":"deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"disable_log_requests": true,
"gpu_memory_utilization": 0.9,
"enforce_eager": true
}Merk op dat de gpu_memory_utilization waarde varieert per GPU en experimenteel bepaald moet worden. Voor deze handleiding gebruiken we 0.9. De directorystructuur binnen ~/model_repository zou er nu als volgt uit moeten zien:
└── deepseek
├── 1
│ └── model.json
└── config.pbtxt
Stel voor het gemak de variabele LOCAL_MODEL_REPOSITORY in:
LOCAL_MODEL_REPOSITORY=~/model_repository/Start de inferentieserver met deze opdracht:
sudo docker run --rm -it --net host --shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 --gpus all -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 tritonserver --model-repository=model_repository/Hier is wat elke parameter doet:
- --rm verwijdert de container automatisch na het stoppen;
- -it draait de container in interactieve modus met terminaluitvoer;
- --net host gebruikt de netwerkstack van de host in plaats van containerisolatie;
- --shm-size=2g stelt gedeeld geheugen in op 2 GB;
- --ulimit memlock=-1 verwijdert geheugen lock limiet;
- --ulimit stack=67108864 stelt stackgrootte in op 64 MB;
- --gpus all maakt toegang tot alle GPU's van de server mogelijk;
- -v $LOCAL_MODEL_REPOSITORY:/opt/tritonserver/model_repository koppelt de lokale modeldirectory in de container;
- nvcr.io/nvidia/tritonserver:25.01-vllm-python-py3 specificeert de container met vLLM backend ondersteuning;
- tritonserver --model-repository=model_repository/ start de Triton-inferentieserver met de locatie van de modellenopslagplaats op model_repository.
Test de server door een verzoek te sturen met curl, met een eenvoudige prompt en een antwoordlimiet van 4096 token:
curl -X POST localhost:8000/v2/models/deepseek/generate -d '{"text_input": "Tell me about the Netherlands?", "max_tokens": 4096}'De server ontvangt en verwerkt het verzoek met succes.
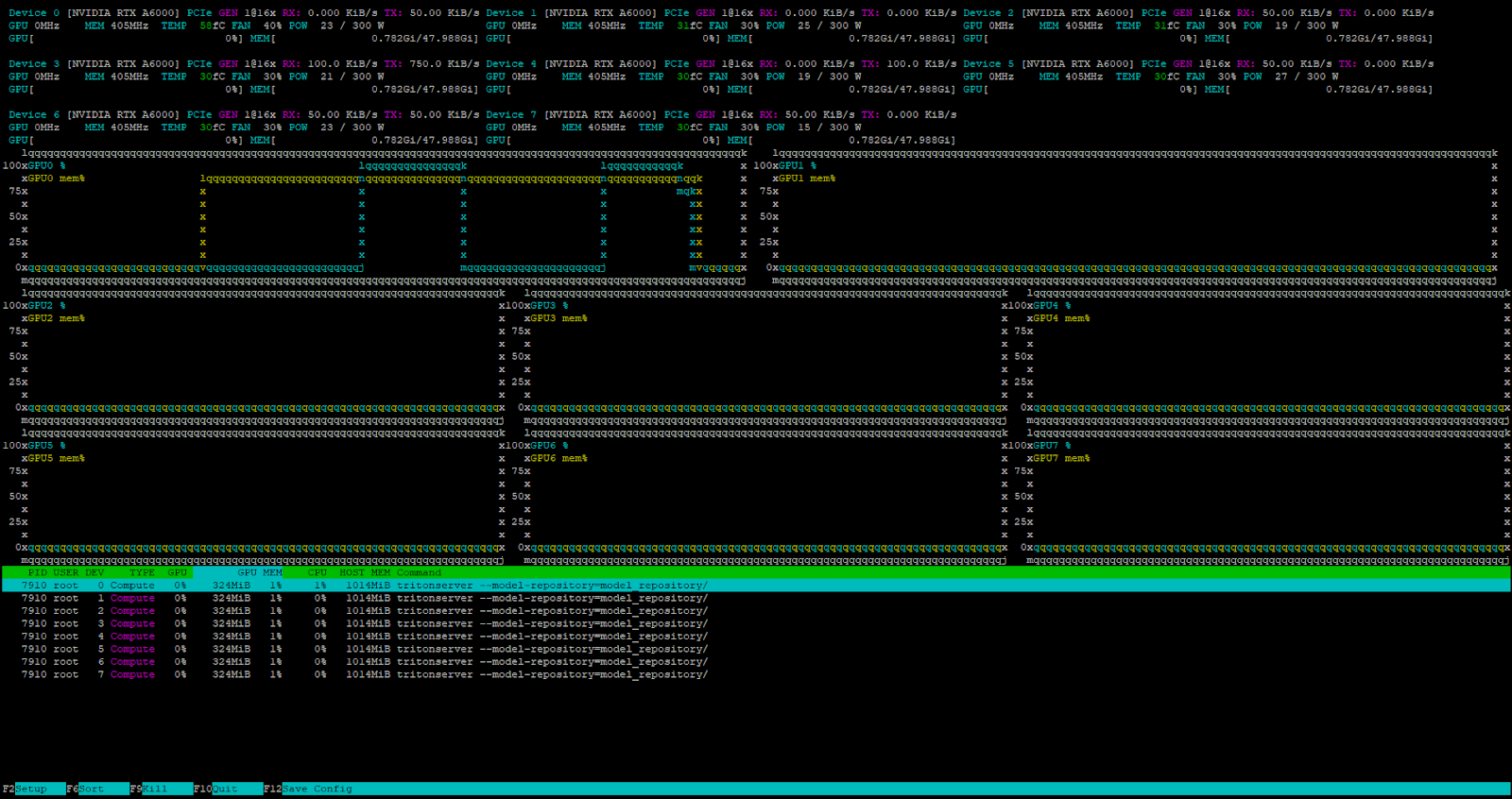
De interne Triton™ taakplanner handelt alle binnenkomende verzoeken af als de server belast is.
Conclusie
Triton™ Inference Server blinkt uit in het inzetten van machine learning-modellen in productie door verzoeken efficiënt te verdelen over beschikbare GPU's. Dit maximaliseert het gebruik van gehuurde serverresources en verlaagt de kosten van de rekeninfrastructuur. Dit maximaliseert het gebruik van gehuurde serverbronnen en verlaagt de kosten van de computerinfrastructuur. De software werkt met verschillende backends, waaronder vLLM voor grote taalmodellen.
Omdat het wordt geïnstalleerd als een Docker-container, kun je het eenvoudig integreren in elke moderne CI/CD-pijplijn. Probeer het zelf door een server van LeaderGPU te huren.
Bijgewerkt: 04.01.2026
Gepubliceerd: 26.02.2025




