





Qwen3-Coder: een gebroken paradigma

We zijn gewend te denken dat open-source modellen qua kwaliteit altijd achterblijven bij hun commerciële tegenhangers. Het lijkt misschien alsof ze uitsluitend worden ontwikkeld door enthousiastelingen die het zich niet kunnen veroorloven om enorme bedragen te investeren in het maken van datasets van hoge kwaliteit en het trainen van modellen op tienduizenden moderne GPU's.
Het is een ander verhaal wanneer grote bedrijven zoals OpenAI, Anthropic of Meta de taak op zich nemen. Zij hebben niet alleen de middelen, maar ook 's werelds beste neurale netwerkspecialisten. Helaas zijn de modellen die ze maken, vooral de laatste versies, closed-source. Ontwikkelaars verklaren dit door te wijzen op de risico's van ongecontroleerd gebruik en de noodzaak om de veiligheid van AI te waarborgen.
Aan de ene kant is hun redenering begrijpelijk: veel ethische vragen zijn nog niet opgelost en de aard van neurale netwerkmodellen laat alleen indirecte invloed toe op de uiteindelijke output. Aan de andere kant is het gesloten houden van modellen en alleen toegang bieden via hun eigen API ook een solide bedrijfsmodel.
Niet alle bedrijven gedragen zich echter zo. Het Franse bedrijf Mistral AI biedt bijvoorbeeld zowel commerciële als open-source modellen aan, zodat onderzoekers en enthousiastelingen ze kunnen gebruiken in hun projecten. Maar er moet speciale aandacht worden besteed aan de prestaties van Chinese bedrijven, waarvan de meeste open-gewicht en open-source modellen bouwen die serieus kunnen concurreren met propriëtaire oplossingen.
DeepSeek, Qwen3 en Kimi K2
De eerste grote doorbraak kwam met DeepSeek-V3. Dit multimodale taalmodel van DeepSeek AI werd ontwikkeld met behulp van de Mixture of Experts (MoE) benadering en indrukwekkende 671B parameters, met 37B meest relevante parameters geactiveerd voor elk token. Het belangrijkste is dat alle componenten (modelgewichten, inferentiecode en trainingspijplijnen) openbaar zijn gemaakt.
Dit maakte het meteen een van de meest aantrekkelijke LLM's voor ontwikkelaars van AI-toepassingen en onderzoekers. De volgende headline-grabber was DeepSeek-R1 - het eerste open-source redeneringsmodel. Op de dag van de release deed het de Amerikaanse aandelenmarkt schudden nadat de ontwikkelaars beweerden dat het trainen van zo'n geavanceerd model slechts $6 miljoen had gekost.
Hoewel de hype rond DeepSeek uiteindelijk afkoelde, waren de volgende releases niet minder belangrijk voor de wereldwijde AI-industrie. We hebben het natuurlijk over Qwen 3. We hebben de functies in detail besproken in onze Nieuw in Qwen 3 review, dus we zullen er hier niet verder op ingaan. Kort daarna verscheen er een andere speler: Kimi K2 van Moonshot AI.
Met zijn MoE architectuur, 1T parameters (32B geactiveerd per token) en open-source code trok Kimi K2 al snel de aandacht van de gemeenschap. Moonshot AI richtte zich niet zozeer op redeneren, maar streefde naar state-of-the-art prestaties op het gebied van wiskunde, programmeren en diepgaande interdisciplinaire kennis.
De troef van Kimi K2 was de optimalisatie voor integratie in AI-agenten. Dit netwerk is letterlijk ontworpen om optimaal gebruik te maken van alle beschikbare hulpmiddelen. Het blinkt uit in taken die niet alleen het schrijven van code vereisen, maar ook iteratief testen in elke ontwikkelingsfase. Het heeft echter ook zwakke punten, die we later zullen bespreken.
Kimi K2 is in alle opzichten een groot taalmodel. Voor het uitvoeren van de volledige versie is ~2 TB VRAM nodig (FP8: ~1 TB). Om voor de hand liggende redenen is dit niet iets wat je thuis kunt doen, en zelfs veel GPU-servers kunnen dit niet aan. Het model heeft ten minste 8 NVIDIA® H200 versnellers nodig. Gekwantiseerde versies kunnen helpen, maar ten koste van de nauwkeurigheid.
Qwen3-coder
Toen Alibaba het succes van Moonshot AI zag, ontwikkelde het zijn eigen Kimi K2-achtige model, maar met belangrijke voordelen die we binnenkort zullen bespreken. Aanvankelijk werd het in twee versies uitgebracht:
- Qwen3-Coder-480B-A35B-Instruct (~250 GB VRAM)
- Qwen3-Coder-480B-A35B-Instruct-FP8 (~120 GB VRAM)
Een paar dagen later verschenen er kleinere modellen zonder het redeneermechanisme, die veel minder VRAM nodig hadden:
- Qwen3-Coder-30B-A3B-Instruct (~32 GB VRAM)
- Qwen3-Coder-30B-A3B-Instruct-FP8 (~18 GB VRAM)
Qwen3-Coder is ontworpen voor integratie met ontwikkeltools. Het bevat een speciale parser voor functie-aanroepen (qwen3coder_tool_parser.py, analoog aan OpenAI's functie-aanroepen). Naast het model werd een console-hulpprogramma uitgebracht, dat in staat is om te proeven van codecompilatie tot het opvragen van een kennisbank. Dit idee is niet nieuw, in wezen is het een sterk herwerkte uitbreiding van Anthropic's Gemini code app.
Het model is compatibel met de OpenAI API, waardoor het lokaal of op een externe server kan worden ingezet en kan worden verbonden met de meeste systemen die deze API ondersteunen. Dit omvat zowel kant-en-klare client apps als machine learning bibliotheken. Dit maakt het niet alleen levensvatbaar voor het B2C-segment maar ook voor het B2B-segment en biedt een naadloze drop-in vervanging voor het product van OpenAI zonder wijzigingen in de applicatielogica.
Een van de meest gevraagde functies is de uitgebreide contextlengte. Standaard ondersteunt het 256k tokens, maar het kan worden uitgebreid tot 1M met behulp van het YaRN (Yet another RoPe extensioN) mechanisme. Moderne LLM's worden meestal getraind op korte datasets (2k-8k tokens) en grote contextlengtes kunnen ervoor zorgen dat ze eerdere inhoud uit het oog verliezen.
YaRN is een elegante "truc" die het model laat denken dat het werkt met de gebruikelijke korte reeksen, terwijl het in werkelijkheid veel langere reeksen verwerkt. Het sleutelidee is om de positionele ruimte "uit te rekken" of te "verwijden" met behoud van de wiskundige structuur die het model verwacht. Dit maakt effectieve verwerking van reeksen van tienduizenden tokens mogelijk zonder hertraining of extra geheugen dat nodig is bij traditionele methoden voor contextuitbreiding.
Inference downloaden en uitvoeren
Zorg ervoor dat je CUDA® van tevoren hebt geïnstalleerd, met behulp van de officiële instructies van NVIDIA® of de gids CUDA-toolkit installeren in Linux. Controleer of de benodigde compiler aanwezig is:
nvcc --versionVerwachte uitvoer:
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2024 NVIDIA Corporation Built on Tue_Feb_27_16:19:38_PST_2024 Cuda compilation tools, release 12.4, V12.4.99 Build cuda_12.4.r12.4/compiler.33961263_0
Als je krijgt:
Command 'nvcc' not found, but can be installed with: sudo apt install nvidia-cuda-toolkit
moet je de CUDA® binaries toevoegen aan $PATH van je systeem.
export PATH=/usr/local/cuda-12.4/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATHDit is een tijdelijke oplossing. Bewerk voor permanent ~/.bashrc en voeg dezelfde twee regels toe aan het einde.
Bereid nu je systeem voor op het beheren van virtuele omgevingen. Je kunt Python's ingebouwde venv gebruiken of het meer geavanceerde Miniforge. Ervan uitgaande dat Miniforge is geïnstalleerd:
conda create -n venv python=3.10conda activate venvInstalleer PyTorch met CUDA® ondersteuning die bij je systeem past:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124Installeer vervolgens de essentiële bibliotheken:
- Transformers - De belangrijkste modelbibliotheek van Hugging Face
- Accelerate - maakt multi-GPU inferentie mogelijk
- HuggingFace Hub - voor het downloaden/uploaden van modellen & datasets
- Safetensors - veilig formaat voor modelgewicht
- vLLM - aanbevolen inferentie bibliotheek voor Qwen
pip install transformers accelerate huggingface_hub safetensors vllmDownload het model:
hf download Qwen/Qwen3-Coder-30B-A3B-Instruct --local-dir ./Qwen3-30BInferentie uitvoeren met tensorparallellisme (laag tensors verdelen over GPU's, bijvoorbeeld 8):
python -m vllm.entrypoints.openai.api_server \
--model /home/usergpu/Qwen3-30B \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.9 \
--dtype auto \
--host 0.0.0.0 \
--port 8000Hiermee wordt de vLLM OpenAI API Server gestart.
Testen en integratie
cURL
Installeer jq voor het mooi afdrukken van JSON:
sudo apt -y install jqTest de server:
curl -s http://127.0.0.1:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "/home/usergpu/Qwen3-30B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello! What can you do?"}
],
"max_tokens": 180
}' | jq -r '.choices[0].message.content'VSCode
Om te integreren met Visual Studio Code, installeer de Continue extensie en voeg toe aan config.yaml:
- name: Qwen3-Coder 30B
provider: openai
apiBase: http://[server_IP_address]:8000/v1
apiKey: none
model: /home/usergpu/Qwen3-30B
roles:
- chat
- edit
- apply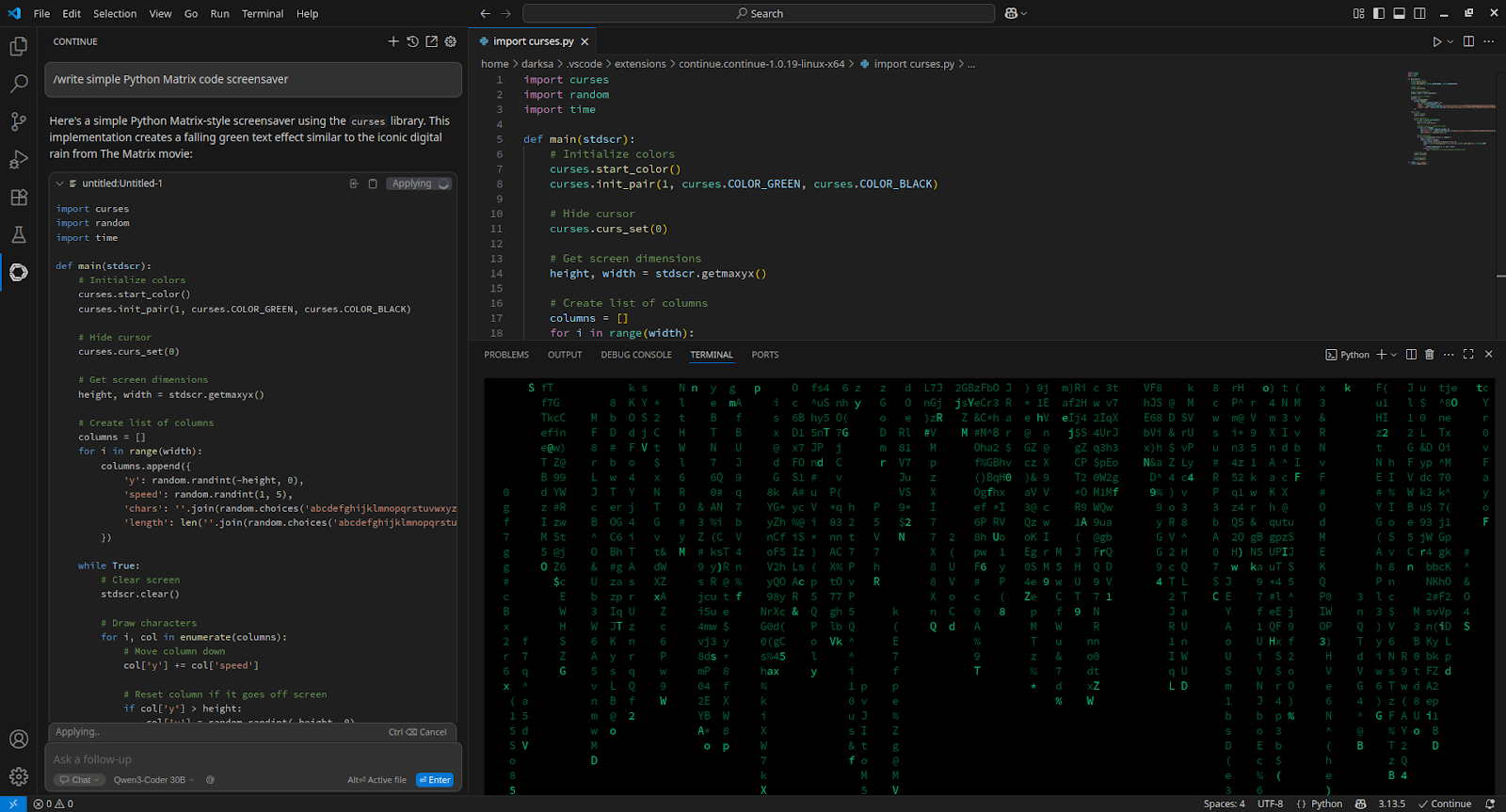
Qwen-Agent
Voor een GUI gebaseerde setup met Qwen-Agent (inclusief RAG, MCP en code interpreter):
pip install -U "qwen-agent[gui,rag,code_interpreter,mcp]"Open de nano editor:
nano script.pyVoorbeeld Python script om Qwen-Agent te starten met een Gradio WebUI:
from qwen_agent.agents import Assistant
from qwen_agent.gui import WebUI
llm_cfg = {
'model': '/home/usergpu/Qwen3-30B',
'model_server': 'http://localhost:8000/v1',
'api_key': 'EMPTY',
'generate_cfg': {'top_p': 0.8},
}
tools = ['code_interpreter']
bot = Assistant(
llm=llm_cfg,
system_message="You are a helpful coding assistant.",
function_list=tools
)
WebUI(bot).run()Voer het script uit:
python script.pyDe server zal beschikbaar zijn op: http://127.0.0.1:7860
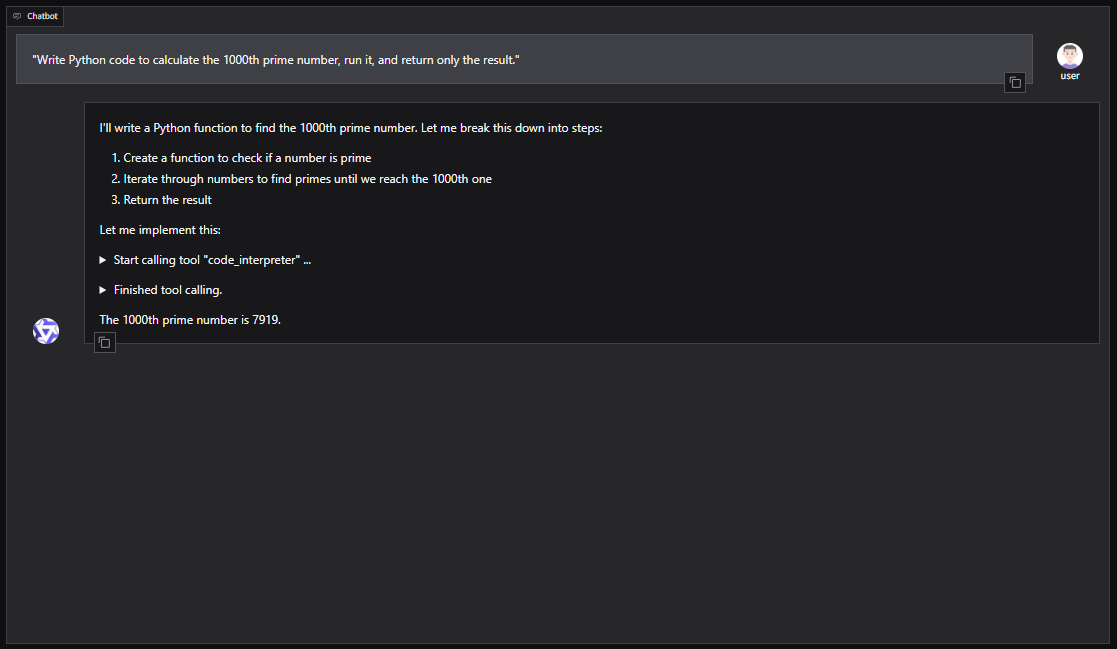
Je kunt Qwen3-Coder ook integreren in agent frameworks zoals CrewAI voor het automatiseren van complexe taken met toolsets zoals web search of vector database memory.
Zie ook:
Bijgewerkt: 04.01.2026
Gepubliceerd: 12.08.2025




