





Je eigen Qwen met HF

Grote neurale netwerkmodellen, met hun buitengewone capaciteiten, zijn stevig verankerd in ons leven. Grote bedrijven zagen dit als een kans voor toekomstige ontwikkeling en begonnen hun eigen versies van deze modellen te ontwikkelen. De Chinese reus Alibaba bleef niet aan de zijlijn staan. Zij creëerden hun eigen model, QWen (Tongyi Qianwen), dat de basis werd voor vele andere neurale netwerkmodellen.
Vereisten
Cache en pakketten bijwerken
Laten we de pakketcache bijwerken en je besturingssysteem upgraden voordat je begint met het instellen van Qwen. Ook moeten we Python Installer Packages (PIP) toevoegen, als het nog niet aanwezig is in het systeem. Voor deze handleiding gebruiken we Ubuntu 22.04 LTS als besturingssysteem:
sudo apt update && sudo apt -y upgrade && sudo apt install python3-pipNvidia-stuurprogramma's installeren
Je kunt het geautomatiseerde hulpprogramma gebruiken dat standaard wordt meegeleverd met Ubuntu-distributies:
sudo ubuntu-drivers autoinstallJe kunt de Nvidia-stuurprogramma's ook handmatig installeren met behulp van onze stapsgewijze handleiding. Vergeet niet de server opnieuw op te starten:
sudo shutdown -r nowTekstgeneratie web UI
Kloon het archief
Open de werkmap op de SSD:
cd /mnt/fastdiskKloon de repository van het project:
git clone https://github.com/oobabooga/text-generation-webui.gitVereisten installeren
Open de gedownloade map:
cd text-generation-webuiControleer en installeer alle ontbrekende onderdelen:
pip install -r requirements.txtSSH-sleutel toevoegen aan HF
Voordat je begint, moet je port forwarding instellen (remote poort 7860 naar 127.0.0.1:7860) in je SSH-client. Meer informatie vind je in het volgende artikel: Verbinding maken met Linux server.
Update de pakketcache repository en geïnstalleerde pakketten:
sudo apt update && sudo apt -y upgradeGenereer en voeg een SSH-sleutel toe die je kunt gebruiken in Hugging Face:
cd ~/.ssh && ssh-keygenWanneer het sleutelpaar is gegenereerd, kun je de publieke sleutel weergeven in de terminal emulator:
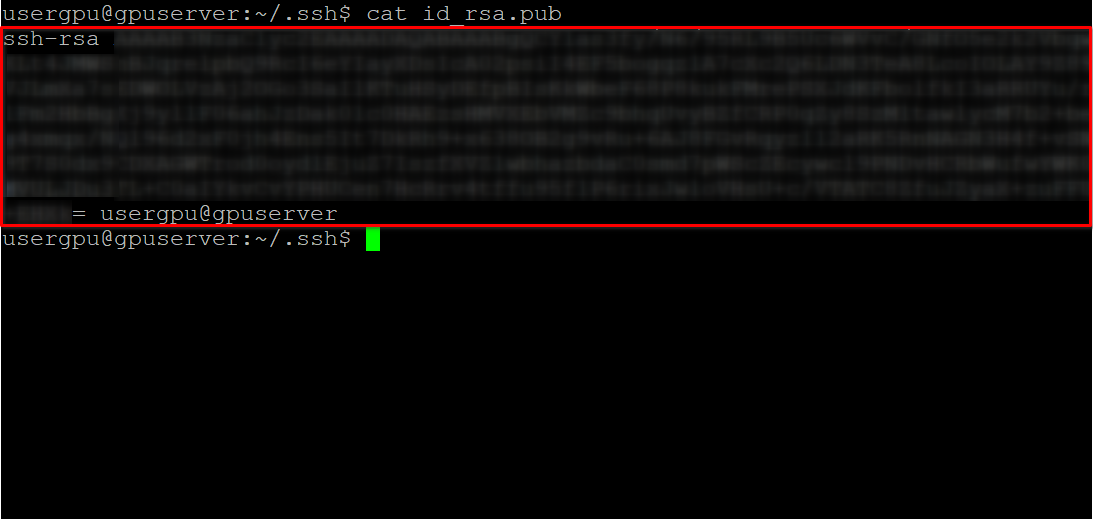
cat id_rsa.pubKopieer alle informatie beginnend bij ssh-rsa en eindigend met usergpu@gpuserver zoals weergegeven in de volgende schermafbeelding:
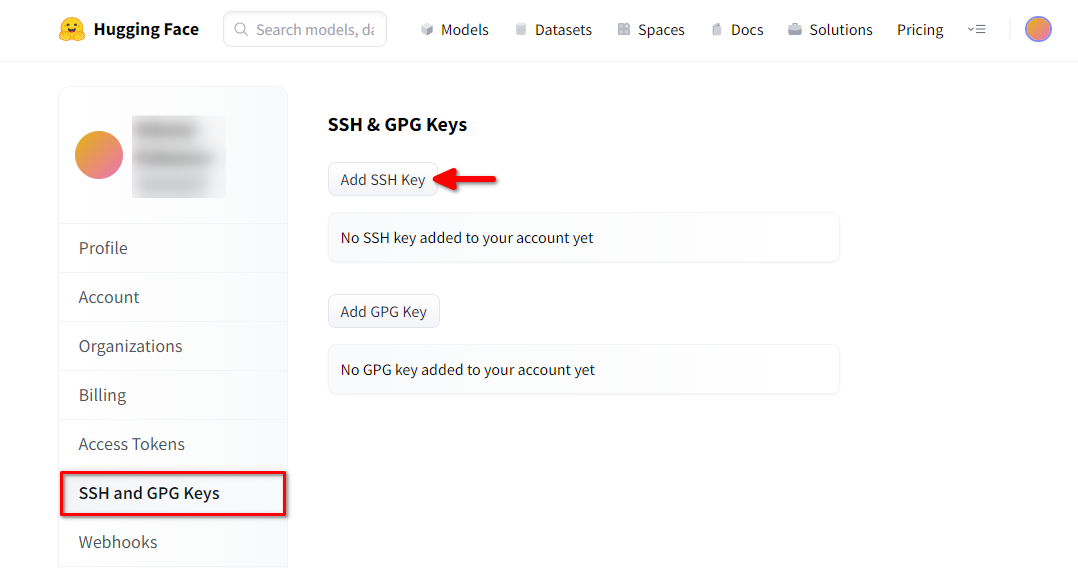
Open een webbrowser, typ https://huggingface.co/ in de adresbalk en druk op Enter. Log in op je HF-account en open Profielinstellingen. Kies dan SSH and GPG Keys en klik op de knop Add SSH Key:
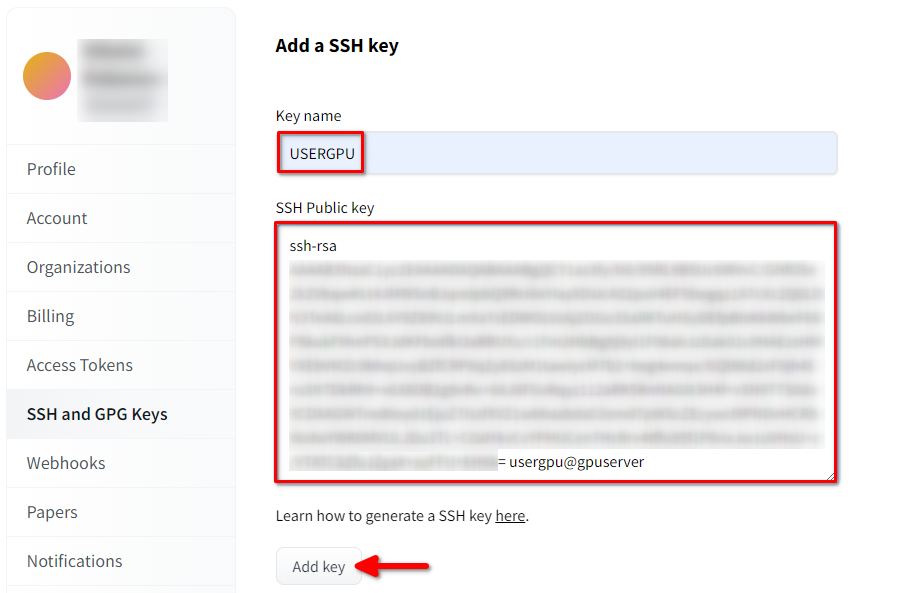
Vul de Key name in en plak de gekopieerde SSH Public key van de terminal. Sla de sleutel op door op Add key te drukken:
Nu is je HF-account gekoppeld aan de publieke SSH-sleutel. Het tweede deel (privésleutel) wordt opgeslagen op de server. De volgende stap is het installeren van een specifieke Git LFS (Large File Storage) extensie, die gebruikt wordt voor het downloaden van grote bestanden zoals neurale netwerkmodellen. Open je home directory:
cd ~/Download en voer het shell script uit. Dit script installeert een nieuwe repository van derden met git-lfs:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashNu kun je het installeren met de standaard pakketbeheerder:
sudo apt-get install git-lfsLaten we git configureren om onze HF nickname te gebruiken:
git config --global user.name "John"En gekoppeld aan het HF e-mail account:
git config --global user.email "john.doe@example.com"Het model downloaden
De volgende stap is het downloaden van het model met behulp van de repository cloning techniek die vaak gebruikt wordt door software ontwikkelaars. Het enige verschil is dat de eerder geïnstalleerde Git-LFS automatisch de gemarkeerde aanwijzingsbestanden zal verwerken en alle inhoud zal downloaden. Open de benodigde map (/mnt/fastdisk in ons voorbeeld):
cd /mnt/fastdiskDit commando kan even duren:
git clone git@hf.co:Qwen/Qwen1.5-32B-Chat-GGUFHet model uitvoeren
Voer een script uit dat de webserver start en /mnt/fastdisk specificeert als de werkmap met modellen. Dit script kan enkele extra componenten downloaden bij de eerste start.
./start_linux.sh --model-dir /mnt/fastdiskOpen uw webbrowser en selecteer llama.cpp in de vervolgkeuzelijst Model loader:
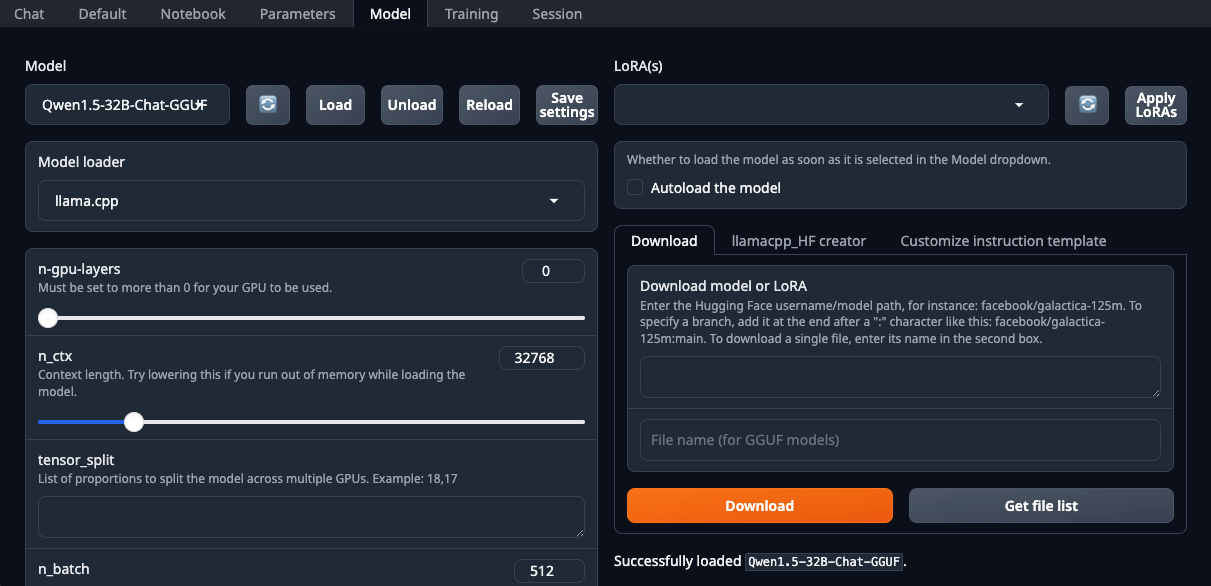
Zorg ervoor dat je de parameter n-gpu-layers instelt. Hij bepaalt welk percentage van de berekeningen wordt overgeheveld naar de GPU. Als je het getal op 0 laat staan, dan worden alle berekeningen uitgevoerd op de CPU, wat vrij traag is. Zodra alle parameters zijn ingesteld, klik je op de knop Load. Ga daarna naar het tabblad Chat en selecteer Instruct mode. Nu kun je een willekeurige prompt invoeren en een antwoord ontvangen:
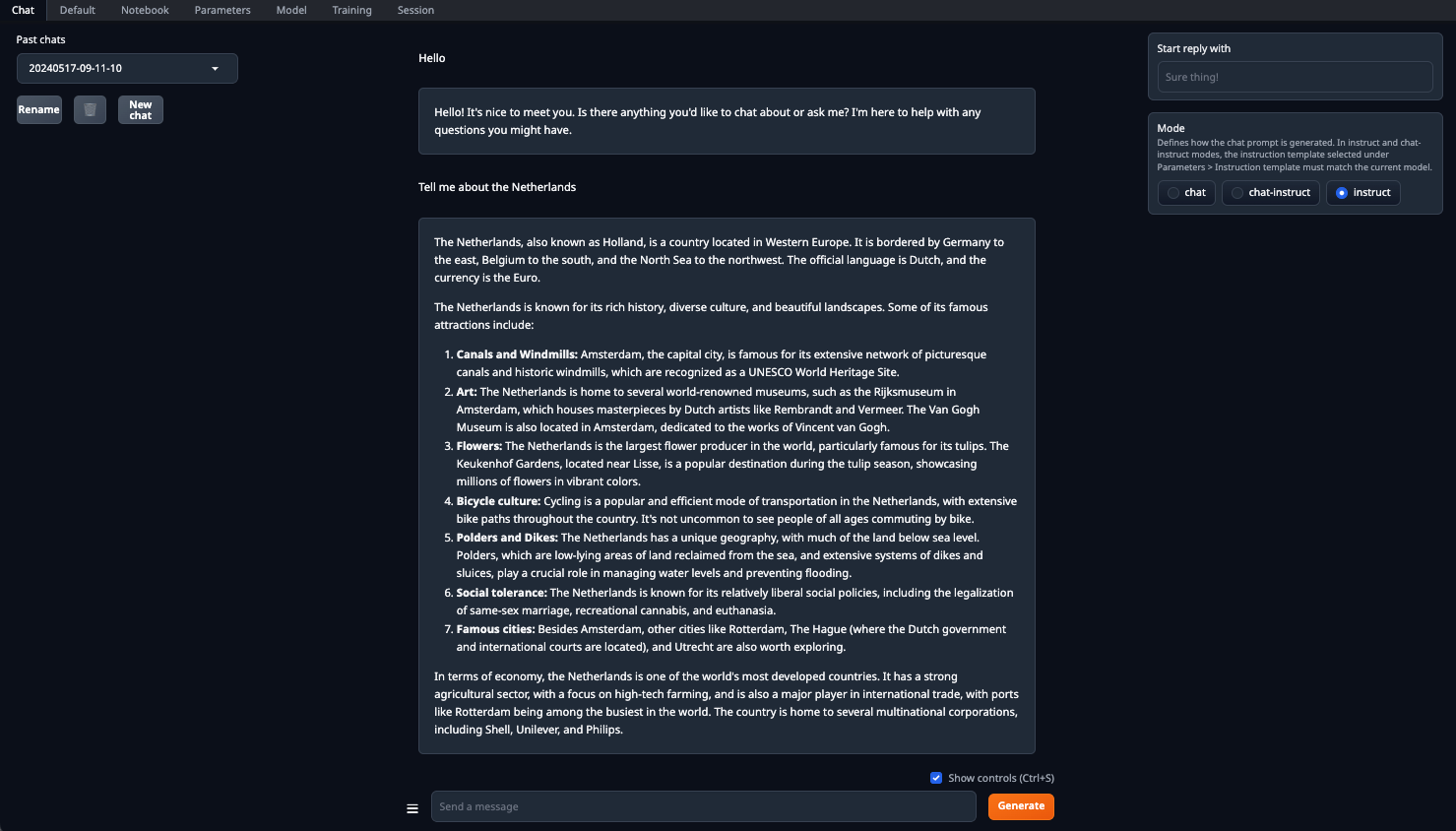
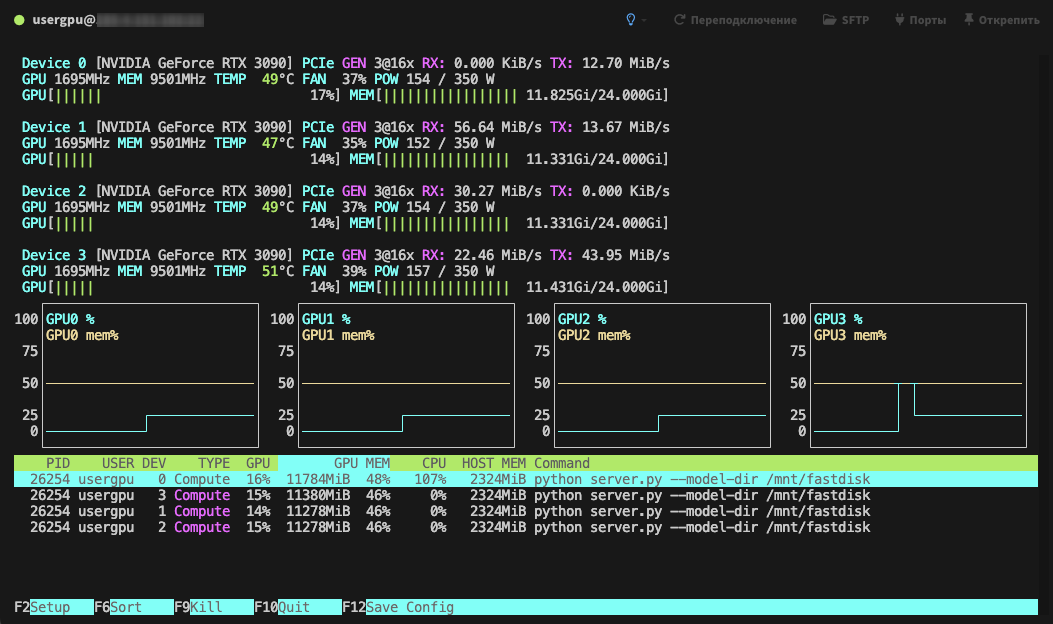
Verwerking wordt standaard uitgevoerd op alle beschikbare GPU's, rekening houdend met de eerder opgegeven parameters:
Zie ook:
Bijgewerkt: 04.01.2026
Gepubliceerd: 20.01.2025




