





Je eigen LLaMa 2 in Linux

Stap 1. Besturingssysteem voorbereiden
Cache en pakketten bijwerken
Laten we de pakketcache bijwerken en je besturingssysteem upgraden voordat je begint met het instellen van LLaMa 2. Houd er rekening mee dat we voor deze gids Ubuntu 22.04 LTS als besturingssysteem gebruiken:
sudo apt update && sudo apt -y upgradeOok moeten we Python Installer Packages (PIP) toevoegen, als het nog niet aanwezig is in het systeem:
sudo apt install python3-pipNvidia-stuurprogramma's installeren
Je kunt het geautomatiseerde hulpprogramma gebruiken dat standaard in Ubuntu-distributies zit:
sudo ubuntu-drivers autoinstallJe kunt de Nvidia-stuurprogramma's ook handmatig installeren met behulp van onze stapsgewijze handleiding. Vergeet niet de server opnieuw op te starten:
sudo shutdown -r nowStap 2. Modellen ophalen bij MetaAI
Officieel verzoek
Open het volgende adres in je browser: https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Vul alle noodzakelijke velden in, lees de gebruikersovereenkomst en klik op de knop Agree and Continue. Na een paar minuten (uren, dagen) ontvang je een speciale download-URL, die je toestemming geeft om modellen voor een periode van 24 uur te downloaden.
Het archief klonen
Controleer voor het downloaden de beschikbare opslagruimte:
df -hFilesystem Size Used Avail Use% Mounted on tmpfs 38G 3.3M 38G 1% /run /dev/sda2 99G 24G 70G 26% / tmpfs 189G 0 189G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock /dev/nvme0n1 1.8T 26G 1.7T 2% /mnt/fastdisk tmpfs 38G 8.0K 38G 1% /run/user/1000
Als je niet-gemounte lokale schijven hebt, volg dan de instructies in Schijfpartitionering in Linux. Dit is belangrijk omdat de gedownloade modellen erg groot kunnen zijn en je hun opslaglocatie van tevoren moet plannen. In dit voorbeeld hebben we een lokale SSD aangekoppeld in de map /mnt/fastdisk. Laten we deze openen:
cd /mnt/fastdiskMaak een kopie van het oorspronkelijke LLaMa archief:
git clone https://github.com/facebookresearch/llamaAls je een toestemmingsfout tegenkomt, verleen dan gewoon toestemmingen aan de gebruikerergpu:
sudo chown -R usergpu:usergpu /mnt/fastdisk/Downloaden via script
Open de gedownloade map:
cd llamaVoer het script uit:
./download.shPlak de URL van MetaAI en selecteer alle benodigde modellen. We raden aan alle beschikbare modellen te downloaden om te voorkomen dat je opnieuw om toestemming moet vragen. Als je echter een specifiek model nodig hebt, download dan alleen dat model.
Snelle test via voorbeeld app
Om te beginnen kunnen we controleren of er componenten ontbreken. Als er bibliotheken of toepassingen ontbreken, zal de pakketbeheerder deze automatisch installeren:
pip install -e .De volgende stap is het toevoegen van nieuwe binaries aan het PATH:
export PATH=/home/usergpu/.local/bin:$PATHVoer het demovoorbeeld uit:
torchrun --nproc_per_node 1 /mnt/fastdisk/llama/example_chat_completion.py --ckpt_dir /mnt/fastdisk/llama-2-7b-chat/ --tokenizer_path /mnt/fastdisk/llama/tokenizer.model --max_seq_len 512 --max_batch_size 6De toepassing maakt een rekenproces aan op de eerste GPU en simuleert een eenvoudige dialoog met typische verzoeken, waarbij antwoorden worden gegenereerd met behulp van LLaMa 2.
Stap 3. Haal llama.cpp op
LLaMa C++ is een project gemaakt door de Bulgaarse natuurkundige en softwareontwikkelaar Georgi Gerganov. Het heeft veel nuttige hulpprogramma's die het werken met dit neurale netwerkmodel eenvoudiger maken. Alle onderdelen van llama.cpp zijn open source software en worden gedistribueerd onder de MIT-licentie.
Kloon de repository
Open de werkmap op de SSD:
cd /mnt/fastdiskKloon de repository van het project:
git clone https://github.com/ggerganov/llama.cpp.gitApps compileren
Open de gekloonde map:
cd llama.cppStart het compilatieproces met de volgende opdracht:
makeStap 4. Tekst-generatie-webui ophalen
Kloon de repository
Open de werkmap op de SSD:
cd /mnt/fastdiskKloon de repository van het project:
git clone https://github.com/oobabooga/text-generation-webui.gitVereisten installeren
Open de gedownloade map:
cd text-generation-webuiControleer en installeer alle ontbrekende onderdelen:
pip install -r requirements.txtStap 5. PTH omzetten naar GGUF
Algemene formaten
PTH (Python TorcH) - Een geconsolideerd formaat. In wezen is het een standaard ZIP-archief met een geserialiseerde PyTorch-statuswoordenboek. Dit formaat heeft echter snellere alternatieven zoals GGML en GGUF.
GGML (Georgi Gerganov’s Machine Learning) - Dit is een bestandsformaat gemaakt door Georgi Gerganov, de auteur van llama.cpp. Het is gebaseerd op een gelijknamige bibliotheek, geschreven in C++, die de prestaties van grote taalmodellen aanzienlijk heeft verbeterd. Het is nu vervangen door het moderne GGUF formaat.
GGUF (Georgi Gerganov’s Unified Format) - Een veelgebruikt bestandsformaat voor LLM's, ondersteund door verschillende toepassingen. Het biedt verbeterde flexibiliteit, schaalbaarheid en compatibiliteit voor de meeste gebruikssituaties.
script llama.cpp converteren.py
Bewerk de parameters van het model voordat het wordt geconverteerd:
nano /mnt/fastdisk/llama-2-7b-chat/params.jsonCorrigeer "vocab_size": -1 naar "vocab_size": 32000. Sla het bestand op en sluit af. Open vervolgens de map llama.cpp:
cd /mnt/fastdisk/llama.cppVoer het script uit dat het model zal converteren naar GGUF formaat:
python3 convert.py /mnt/fastdisk/llama-2-7b-chat/ --vocab-dir /mnt/fastdisk/llamaAls alle voorgaande stappen juist zijn, krijg je een bericht als dit:
Wrote /mnt/fastdisk/llama-2-7b-chat/ggml-model-f16.gguf
Stap 6. WebUI
WebUI starten
Open de map:
cd /mnt/fastdisk/text-generation-webui/Voer het startscript uit met enkele nuttige parameters:
- --model-dir geeft het juiste pad naar de modellen aan
- --share creëert een tijdelijke publieke link (als je geen poort wilt doorsturen via SSH)
- --gradio-auth voegt autorisatie toe met een login en wachtwoord (vervang user:wachtwoord door je eigen)
./start_linux.sh --model-dir /mnt/fastdisk/llama-2-7b-chat/ --share --gradio-auth user:passwordNa een succesvolle lancering ontvang je een lokale en tijdelijke share link voor toegang:
Running on local URL: http://127.0.0.1:7860 Running on public URL: https://e9a61c21593a7b251f.gradio.live
Deze share link verloopt over 72 uur.
Het model laden
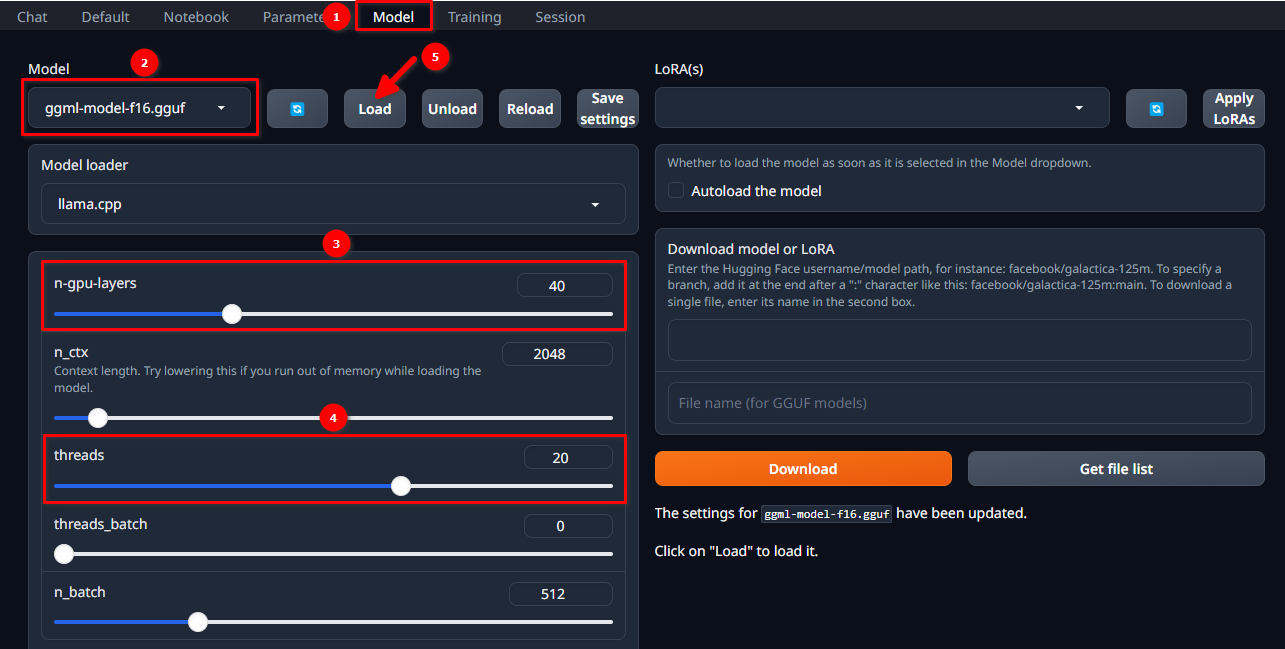
Autoriseer in de WebUI met de geselecteerde gebruikersnaam en wachtwoord en volg deze 5 eenvoudige stappen:
- Navigeer naar het tabblad Model.
- Selecteer ggml-model-f16.gguf in het vervolgkeuzemenu.
- Kies hoeveel lagen je wilt berekenen op de GPU (n-gpu-layers).
- Kies hoeveel threads je wilt starten (threads).
- Klik op de knop Load.
Het dialoogvenster starten
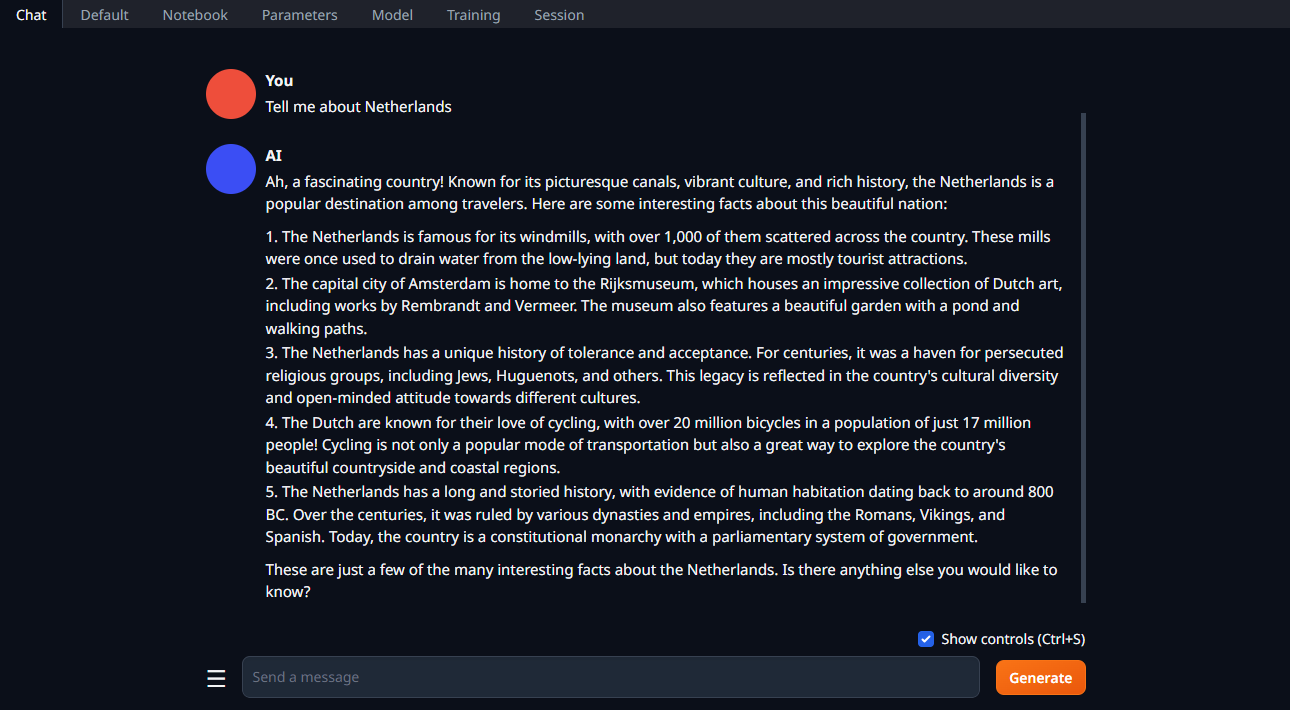
Verander de tab in Chat, typ je vraag en klik op Generate:
Zie ook:
Bijgewerkt: 04.01.2026
Gepubliceerd: 20.01.2025




