





Qwen 2 vs Llama 3

Grote taalmodellen (LLM's) hebben ons leven aanzienlijk beïnvloed. Ondanks dat we hun interne structuur begrijpen, blijven deze modellen een aandachtspunt voor wetenschappers die ze vaak vergelijken met een "zwarte doos". Het uiteindelijke resultaat hangt niet alleen af van het ontwerp van de LLM, maar ook van de training en de gegevens die voor de training zijn gebruikt.
Terwijl wetenschappers op zoek gaan naar onderzoeksmogelijkheden, zijn eindgebruikers vooral geïnteresseerd in twee dingen: snelheid en kwaliteit. Deze criteria spelen een cruciale rol in het selectieproces. Om twee LLM's nauwkeurig met elkaar te vergelijken, moeten veel schijnbaar ongerelateerde factoren worden gestandaardiseerd.
De apparatuur die wordt gebruikt voor interferentie en de softwareomgeving, inclusief het besturingssysteem, driverversies en softwarepakketten, hebben de grootste invloed. Het is essentieel om een LLM-versie te kiezen die op verschillende apparatuur werkt en een snelheidsmeting te kiezen die gemakkelijk te begrijpen is.
We hebben gekozen voor 'tokens per seconde' (tokens/s) als deze metriek. Het is belangrijk om te weten dat een token ≠ een woord is. De LLM splitst woorden op in eenvoudigere componenten, typisch voor een specifieke taal, die tokens worden genoemd.
De statistische voorspelbaarheid van het volgende teken verschilt per taal, dus de tokenisatie zal verschillen. In het Engels worden bijvoorbeeld ongeveer 100 tokens afgeleid uit elke 75 woorden. In talen die het cyrillische alfabet gebruiken, kan het aantal tokens per woord hoger zijn. Dus 75 woorden in een cyrillische taal, zoals Russisch, kunnen gelijkstaan aan 120-150 tokens.
Je kunt dit controleren met het gereedschap Tokenizer van OpenAI. Deze laat zien in hoeveel tokens een tekstfragment is opgedeeld, waardoor 'tokens per seconde' een goede indicator is voor de snelheid en prestaties van een LLM op het gebied van natuurlijke taalverwerking.
Elke test werd uitgevoerd op het Ubuntu 22.04 LTS besturingssysteem met NVIDIA® drivers versie 535.183.01 en de NVIDIA® CUDA® 12.5 Toolkit geïnstalleerd. Er werden vragen geformuleerd om de kwaliteit en snelheid van de LLM te beoordelen. De verwerkingssnelheid van elk antwoord werd geregistreerd en zal bijdragen aan de gemiddelde waarde voor elke geteste configuratie.
We begonnen met het testen van verschillende GPU's, van de nieuwste modellen tot de oudere. Een cruciale voorwaarde voor de test was dat we de prestaties van slechts één GPU maten, zelfs als er meerdere aanwezig waren in de serverconfiguratie. De prestaties van een configuratie met meerdere GPU's zijn namelijk afhankelijk van extra factoren, zoals de aanwezigheid van een snelle interconnect tussen de GPU's (NVLink).
Naast snelheid hebben we ook geprobeerd de kwaliteit van de antwoorden te evalueren op een 5-puntsschaal, waarbij 5 staat voor het beste resultaat. Deze informatie wordt hier alleen gegeven voor algemeen begrip. Elke keer stellen we dezelfde vragen aan het neurale netwerk en proberen we te achterhalen hoe nauwkeurig elk netwerk begrijpt wat de gebruiker wil.
Qwen 2
Onlangs presenteerde een team ontwikkelaars van Alibaba Group de tweede versie van hun generatieve neurale netwerk Qwen. Het begrijpt 27 talen en is er goed voor geoptimaliseerd. Qwen 2 wordt geleverd in verschillende groottes, zodat het eenvoudig kan worden ingezet op elk apparaat (van embedded systemen met veel bronnen tot een speciale server met GPU's):
- 0.5B: geschikt voor IoT en embedded systemen;
- 1,5B: een uitgebreide versie voor ingebedde systemen, gebruikt waar de mogelijkheden van 0,5B niet voldoende zijn;
- 7B: middelgroot model, zeer geschikt voor natuurlijke taalverwerking;
- 57B: groot model met hoge prestaties, geschikt voor veeleisende toepassingen;
- 72B: het ultieme Qwen 2 model, ontworpen om de meest complexe problemen op te lossen en grote hoeveelheden data te verwerken.
Versies 0.5B en 1.5B werden getraind op datasets met een contextlengte van 32K. Versies 7B en 72B waren al getraind op de 128K context. Het compromismodel 57B werd getraind op datasets met een contextlengte van 64K. De makers positioneren Qwen 2 als een analogon van Llama 3 die dezelfde problemen kan oplossen, maar dan veel sneller.
Llama 3
De derde versie van het generatieve neurale netwerk van de MetaAI Llama familie werd geïntroduceerd in april 2024. Het werd, in tegenstelling tot Qwen 2, in slechts twee versies uitgebracht: 8B en 70B. Deze modellen werden gepositioneerd als een universeel hulpmiddel voor het oplossen van veel problemen in verschillende gevallen. Het zette de trend naar meertaligheid en multimodaliteit voort, terwijl het tegelijkertijd sneller werd dan de vorige versies en een langere contextlengte ondersteunde.
De makers van Llama 3 probeerden de modellen te verfijnen om het percentage statistische hallucinaties te verminderen en de variatie in antwoorden te vergroten. Llama 3 is dus heel goed in staat om praktisch advies te geven, te helpen bij het schrijven van een zakelijke brief of te speculeren over een door de gebruiker gespecificeerd onderwerp. De datasets waarop Llama 3 modellen werden getraind hadden een contextlengte van 128K en meer dan 5% bevatte gegevens in 30 talen. Echter, zoals vermeld in het persbericht, zullen de generatieprestaties in het Engels significant hoger zijn dan in elke andere taal.
Vergelijking
NVIDIA® RTX™ A6000
Laten we onze snelheidsmetingen beginnen met de NVIDIA® RTX™ A6000 GPU, gebaseerd op de Ampere architectuur (niet te verwarren met de NVIDIA® RTX™ A6000 Ada). Deze kaart heeft zeer bescheiden eigenschappen, maar heeft tegelijkertijd 48 GB VRAM, waardoor het met redelijk grote neurale netwerkmodellen kan werken. Helaas zijn de lage kloksnelheid en bandbreedte de redenen voor de lage inferentiesnelheid van tekst LLM's.
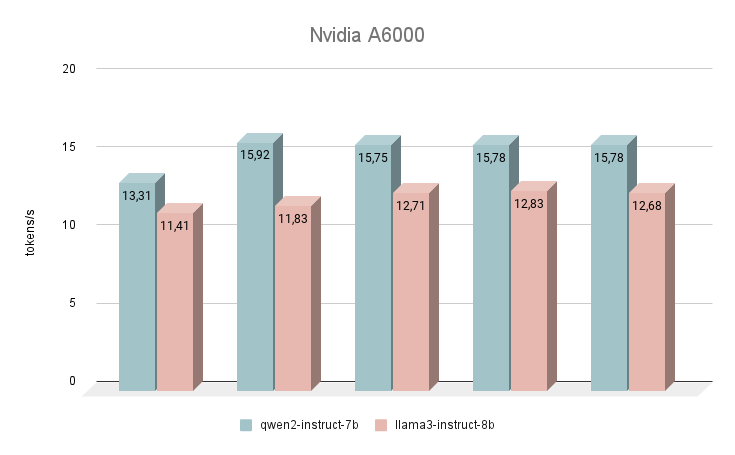
Onmiddellijk na de lancering begon het Qwen 2 neurale netwerk beter te presteren dan Llama 3. Bij het beantwoorden van dezelfde vragen was het gemiddelde snelheidsverschil 24% in het voordeel van Qwen 2. De snelheid waarmee antwoorden werden gegenereerd lag in het bereik van 11-16 tokens per seconde. Dit is 2-3 keer sneller dan wanneer je zelfs op een krachtige CPU probeert te genereren, maar in onze beoordeling is dit het meest bescheiden resultaat.
NVIDIA® RTX™ 3090
De volgende GPU is ook gebouwd op de Ampere-architectuur, heeft 2 keer minder videogeheugen, maar werkt tegelijkertijd op een hogere frequentie (19500 MHz versus 16000 Mhz). De bandbreedte van het videogeheugen is ook hoger (936,2 GB/s tegenover 768 GB/s). Beide factoren verhogen de prestaties van de RTX™ 3090 aanzienlijk, zelfs als we rekening houden met het feit dat deze 256 CUDA-kernen minder heeft.
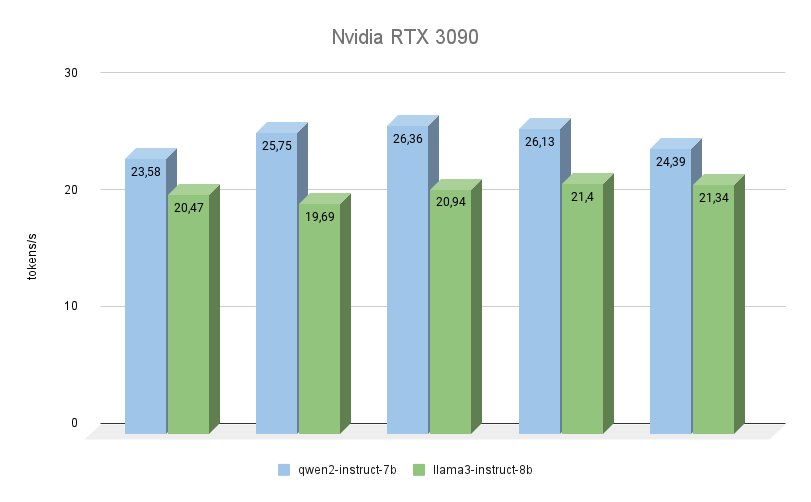
Hier kun je duidelijk zien dat Qwen 2 veel sneller is (tot 23%) dan Llama 3 bij het uitvoeren van dezelfde taken. Wat betreft de kwaliteit van het genereren, is de meertalige ondersteuning van Qwen 3 echt een pluim waard, en het model antwoordt altijd in dezelfde taal als waarin de vraag is gesteld. Met Llama 3 komt het in dit opzicht vaak voor dat het model de vraag zelf begrijpt, maar er de voorkeur aan geeft antwoorden in het Engels te formuleren.
NVIDIA® RTX™ 4090
Nu het meest interessante: laten we eens kijken hoe de NVIDIA® RTX™ 4090, gebouwd op de Ada Lovelace-architectuur, genoemd naar de Engelse wiskundige Augusta Ada King, gravin van Lovelace, dezelfde taak aankan. Ze werd beroemd omdat ze de eerste programmeur in de geschiedenis van de mensheid was, en op het moment dat ze haar eerste programma schreef was er nog geen computer die het kon uitvoeren. Wel werd erkend dat het algoritme dat Ada beschreef voor het berekenen van Bernoulli getallen het eerste programma ter wereld was dat geschreven werd om op een computer te spelen.
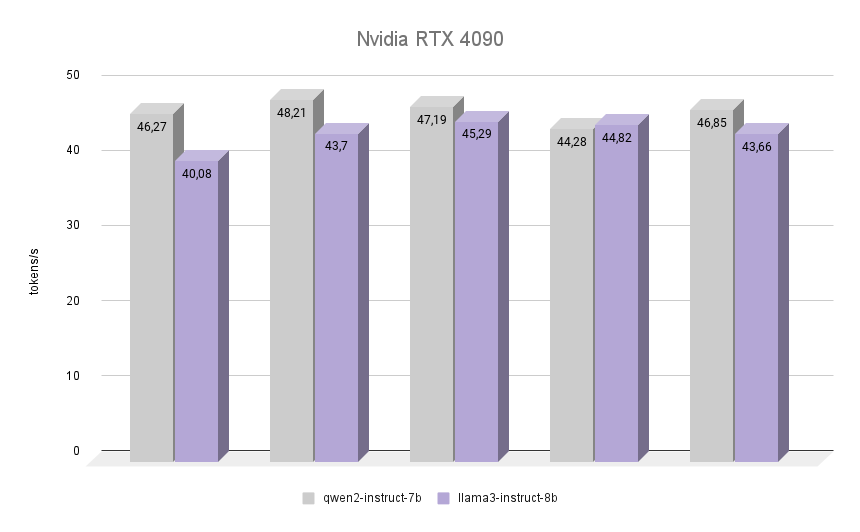
De grafiek laat duidelijk zien dat de RTX™ 4090 de inferentie van beide modellen bijna twee keer zo snel uitvoerde. Het is interessant dat in een van de iteraties Llama 3 erin slaagde om Qwen 2 met 1,2% te overtreffen. Rekening houdend met de andere iteraties behield Qwen 2 echter zijn leiderschap en bleef 7% sneller dan Llama 3. In alle iteraties was de kwaliteit van de antwoorden van beide neurale netwerken hoog met een minimaal aantal hallucinaties. Het enige defect is dat in zeldzame gevallen een of twee Chinese karakters werden gemengd in de antwoorden, wat op geen enkele manier de algehele betekenis beïnvloedde.
NVIDIA® RTX™ A40
De volgende NVIDIA® RTX™ A40-kaart, waarop we vergelijkbare tests uitvoerden, is opnieuw gebouwd op de Ampere-architectuur en heeft 48 GB videogeheugen op het moederbord. Vergeleken met de RTX™ 3090 is dit geheugen iets sneller (20000 MHz versus 19500 MHz), maar heeft het een lagere bandbreedte (695,8 GB/s versus 936,2 GB/s). Deze situatie wordt gecompenseerd door het grotere aantal CUDA-kernen (10752 tegenover 10496), waardoor de RTX™ A40 over het geheel genomen iets sneller presteert dan de RTX™ 3090.
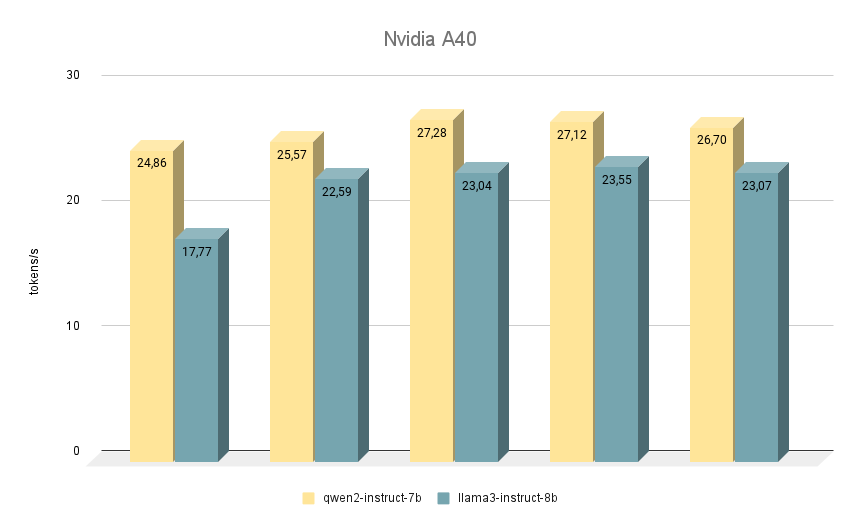
Wat betreft het vergelijken van de snelheid van modellen, hier ligt Qwen 2 ook voor op Llama 3 in alle iteraties. Bij het draaien op RTX™ A40 is het verschil in snelheid ongeveer 15% met dezelfde antwoorden. Bij sommige opgaven gaf Qwen 2 iets meer belangrijke informatie, terwijl Llama 3 zo specifiek mogelijk was en voorbeelden gaf. Desondanks moet alles dubbel gecontroleerd worden, omdat beide modellen soms controversiële antwoorden geven.
NVIDIA® L20
De laatste deelnemer aan onze tests was de NVIDIA® L20. Deze GPU is net als de RTX™ 4090 gebouwd op de Ada Lovelace-architectuur. Dit is een vrij nieuw model, gepresenteerd in de herfst van 2023. Hij heeft 48 GB videogeheugen en 11776 CUDA-kernen aan boord. De geheugenbandbreedte is lager dan die van de RTX™ 4090 (864 GB/s tegenover 936,2 GB/s), net als de effectieve frequentie. Dus de NVIDIA® L20 inferentiescores van beide modellen zullen dichter bij 3090 liggen dan bij 4090.
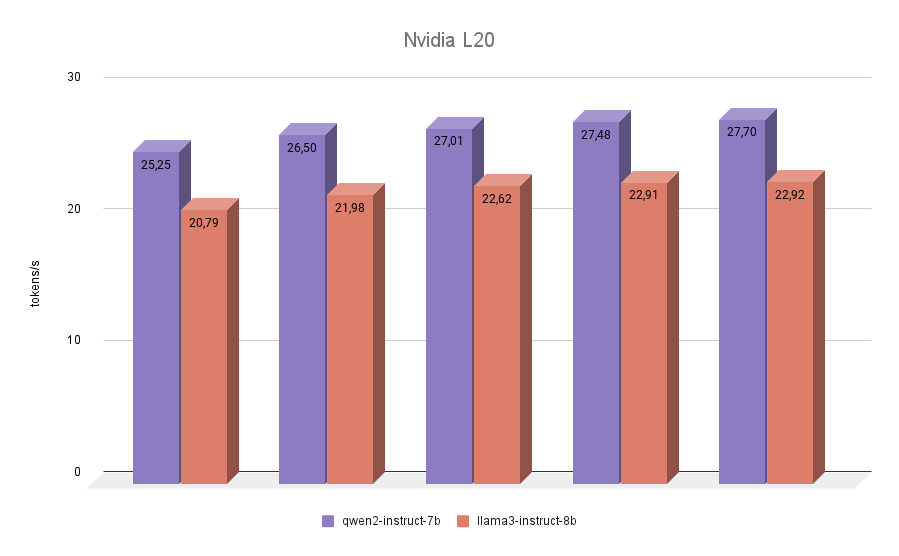
De laatste test leverde geen verrassingen op. Qwen 2 bleek in alle iteraties sneller dan Llama 3.
Conclusie
Laten we alle verzamelde resultaten samenvoegen in één grafiek. Qwen 2 was 7% tot 24% sneller dan Llama 3, afhankelijk van de gebruikte GPU. Op basis hiervan kunnen we duidelijk concluderen dat als je hogesnelheidsinferenties nodig hebt van modellen zoals Qwen 2 of Llama 3 op single-GPU configuraties, de RTX™ 3090 de onbetwiste leider is. Een mogelijk alternatief zou de A40 of L20 kunnen zijn. Maar het is niet de moeite waard om de inferentie van deze modellen uit te voeren op A6000-generatie Ampere-kaarten.

We hebben met opzet kaarten met een kleinere hoeveelheid videogeheugen, bijvoorbeeld NVIDIA® RTX™ 2080Ti, niet genoemd in de tests, omdat het daar niet mogelijk is om de bovengenoemde 7B of 8B modellen in te passen zonder kwantisatie. Welnu, het 1,5B model Qwen 2 heeft helaas geen antwoorden van hoge kwaliteit en kan niet dienen als volledige vervanging voor 7B.
Zie ook:
Bijgewerkt: 04.01.2026
Gepubliceerd: 20.01.2025




