





Llama 3 met Hugging Face

Op 18 april 2024 werd het nieuwste grote taalmodel van MetaAI, Llama 3, uitgebracht. Er werden twee versies aan gebruikers gepresenteerd: 8B en 70B. De eerste versie bevat meer dan 15K tokens en werd getraind op gegevens die geldig waren tot maart 2023. De tweede, grotere versie is getraind op gegevens die geldig zijn tot december 2023.
Stap 1. Besturingssysteem voorbereiden
Cache en pakketten bijwerken
Laten we de pakketcache bijwerken en je besturingssysteem upgraden voordat je begint met het instellen van LLaMa 3. Houd er rekening mee dat we voor deze gids Ubuntu 22.04 LTS als besturingssysteem gebruiken:
sudo apt update && sudo apt -y upgradeOok moeten we Python Installer Packages (PIP) toevoegen, als het nog niet aanwezig is in het systeem:
sudo apt install python3-pipNvidia-stuurprogramma's installeren
Je kunt het geautomatiseerde hulpprogramma gebruiken dat standaard in Ubuntu-distributies zit:
sudo ubuntu-drivers autoinstallJe kunt de Nvidia-stuurprogramma's ook handmatig installeren. Vergeet niet de server opnieuw op te starten:
sudo shutdown -r nowStap 2. Het model ophalen
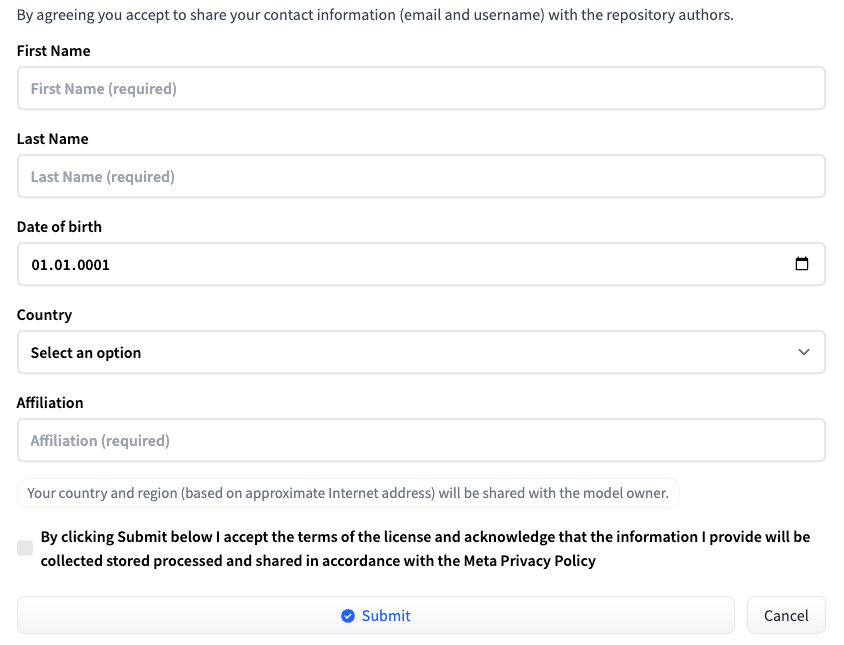
Log in op Hugging Face met uw gebruikersnaam en wachtwoord. Ga naar de pagina die bij de gewenste LLM-versie hoort: Meta-Llama-3-8B of Meta-Llama-3-70B. Op het moment van publicatie van dit artikel wordt toegang tot het model op individuele basis verleend. Vul een kort formulier in en klik op de knop Submit:
Toegang aanvragen bij HF
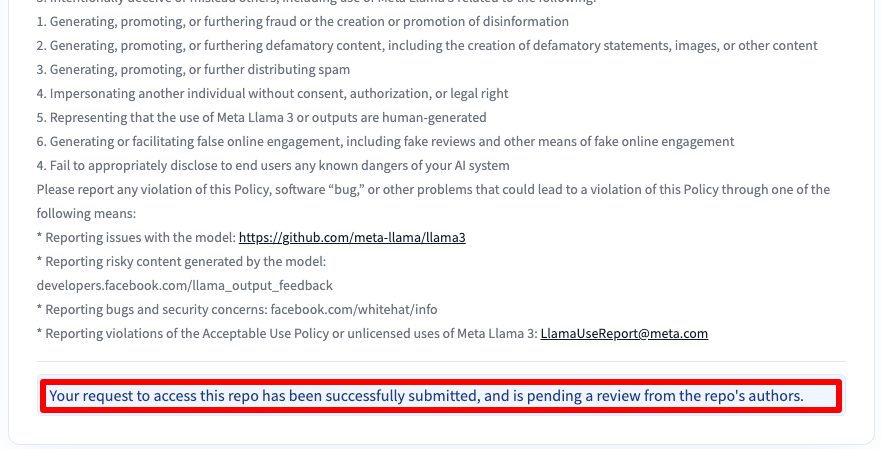
Vervolgens ontvang je een bericht dat je verzoek is ingediend:
Na 30-40 minuten krijg je toegang en ontvang je hierover bericht via e-mail.
SSH-sleutel toevoegen aan HF
Genereer en voeg een SSH-sleutel toe die je kunt gebruiken in Hugging Face:
cd ~/.ssh && ssh-keygenWanneer het sleutelpaar is gegenereerd, kun je de publieke sleutel weergeven in de terminal emulator:
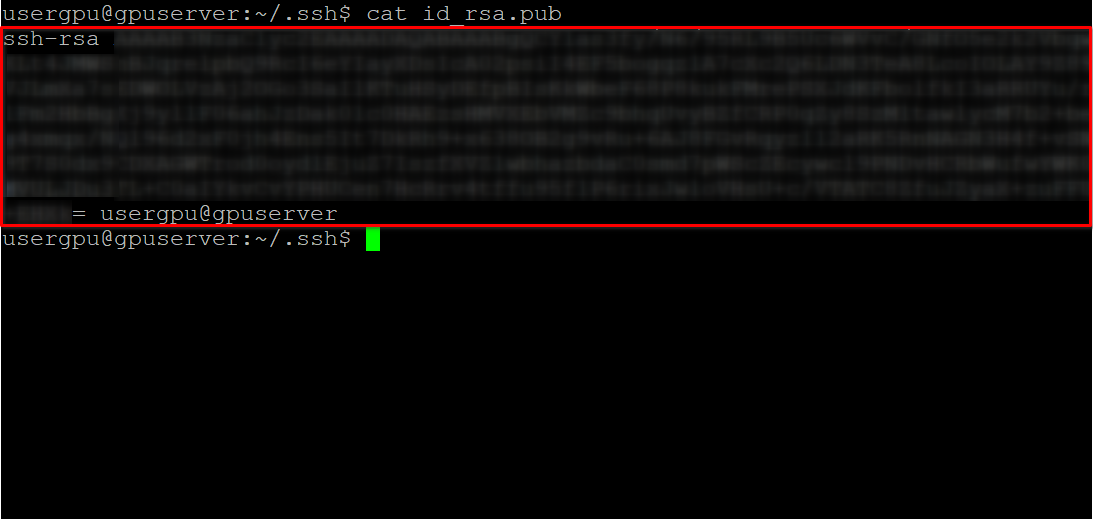
cat id_rsa.pubKopieer alle informatie beginnend bij ssh-rsa en eindigend bij usergpu@gpuserver zoals weergegeven in de volgende schermafbeelding:
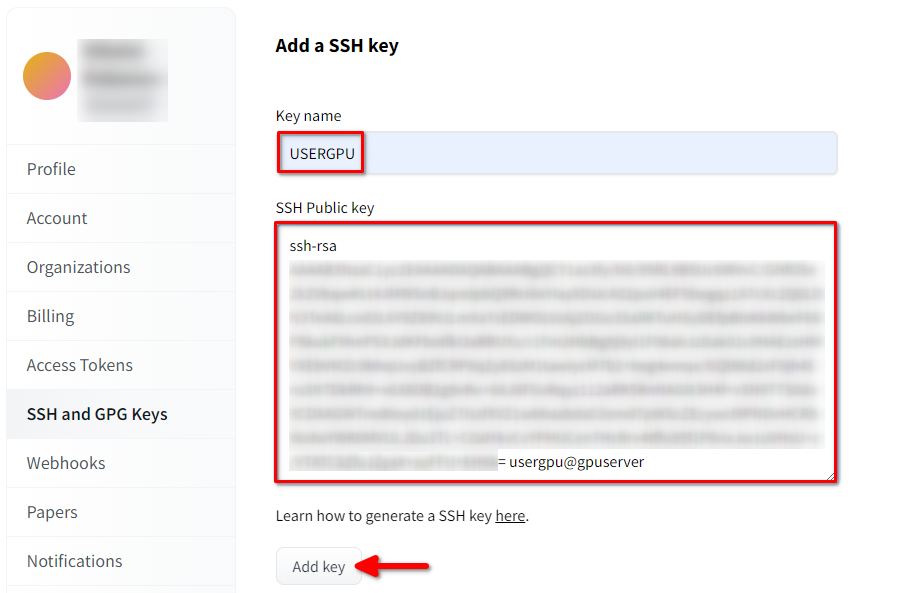
Open Hugging Face Profielinstellingen. Kies vervolgens SSH and GPG Keys en klik op de knop SSH-sleutel toevoegen:
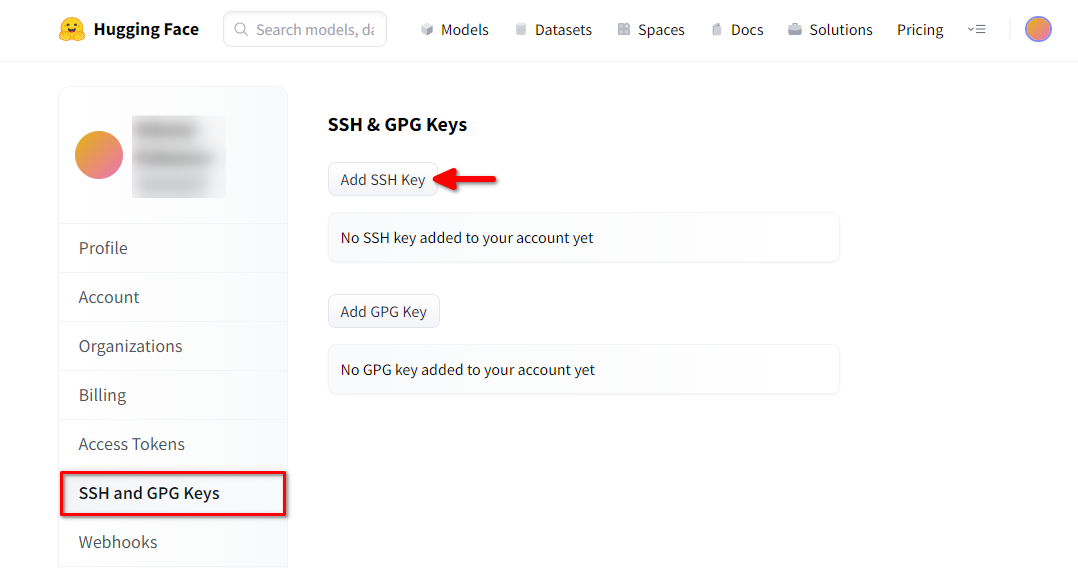
Vul de Key name in en plak de gekopieerde SSH Public key van de terminal. Sla de sleutel op door op Add key te drukken:
Nu is je HF-account gekoppeld aan de publieke SSH-sleutel. Het tweede deel (privésleutel) wordt opgeslagen op de server. De volgende stap is het installeren van een specifieke Git LFS (Large File Storage) extensie, die gebruikt wordt voor het downloaden van grote bestanden zoals neurale netwerkmodellen. Open je home directory:
cd ~/Download en voer het shell script uit. Dit script installeert een nieuwe repository van derden met git-lfs:
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bashNu kun je het installeren met de standaard pakketbeheerder:
sudo apt-get install git-lfsLaten we git configureren om onze HF nickname te gebruiken:
git config --global user.name "John"En gekoppeld aan het HF e-mail account:
git config --global user.email "john.doe@example.com"Het model downloaden
Open de doelmap:
cd /mnt/fastdiskEn begin met het downloaden van de repository. Voor dit voorbeeld kiezen we versie 8B:
git clone git@hf.co:meta-llama/Meta-Llama-3-8BDit proces duurt maximaal 5 minuten. Je kunt dit controleren door het volgende commando in een andere SSH-console uit te voeren:
watch -n 0.5 df -hHier zie je hoe de vrije schijfruimte op de gemounte schijf afneemt, wat ervoor zorgt dat de download vordert en de gegevens worden opgeslagen. De status wordt elke halve seconde vernieuwd. Om het bekijken handmatig te stoppen, druk je op de sneltoets Ctrl + C.
Je kunt ook btop installeren en het proces volgen met dit hulpprogramma:
sudo apt -y install btop && btop
Om het hulpprogramma btop af te sluiten, druk je op de toets Esc en selecteer je Quit.
Stap 3. Het model uitvoeren
Open de map:
cd /mnt/fastdiskDownload de Llama 3 repository:
git clone https://github.com/meta-llama/llama3Wijzig de map:
cd llama3Voer het voorbeeld uit:
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir /mnt/fastdisk/Meta-Llama-3-8B/original \
--tokenizer_path /mnt/fastdisk/Meta-Llama-3-8B/original/tokenizer.model \
--max_seq_len 128 \
--max_batch_size 4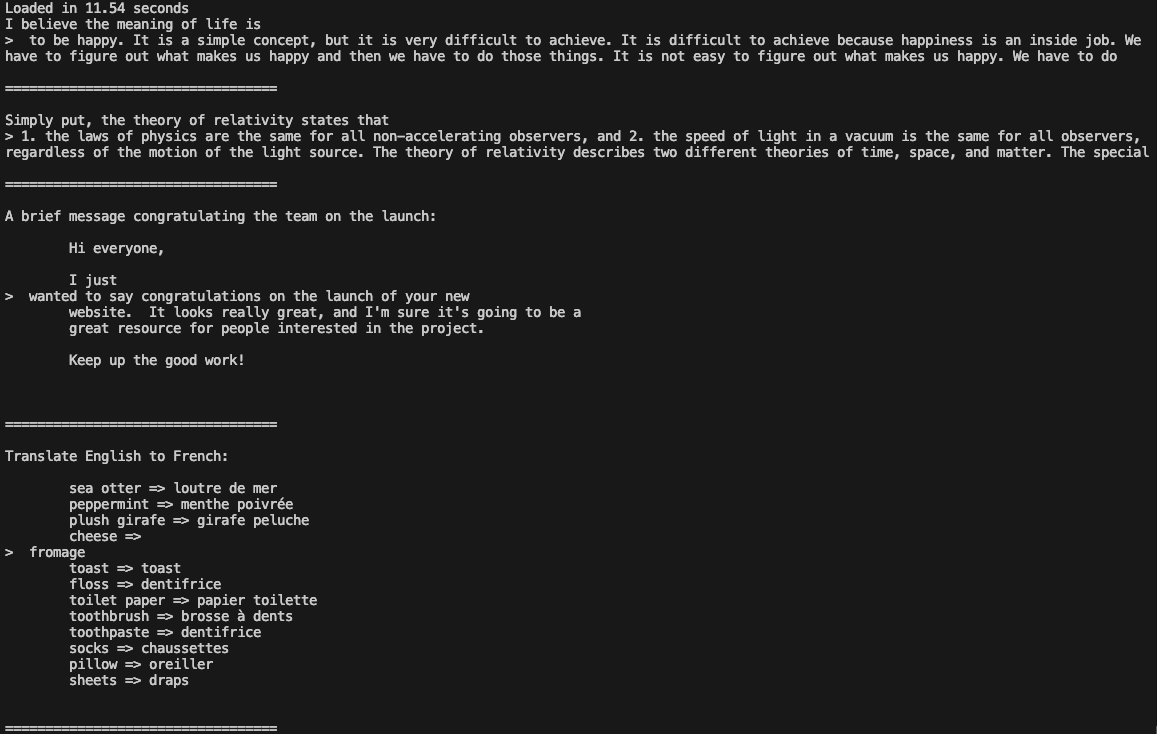
Nu kun je Llama 3 gebruiken in je applicaties.
Zie ook:
Bijgewerkt: 04.01.2026
Gepubliceerd: 20.01.2025




