





Hoe werkt Ollama

Ollama is een hulpmiddel om grote neurale netwerkmodellen lokaal uit te voeren. Het gebruik van openbare diensten wordt door bedrijven vaak gezien als een potentieel risico voor het lekken van vertrouwelijke en gevoelige gegevens. Door LLM op een gecontroleerde server te implementeren, kunt u de gegevens die erop staan onafhankelijk beheren terwijl u gebruik maakt van de sterke punten van LLM.
Dit helpt ook om de onaangename situatie van vendor lock-in te voorkomen, waarbij elke openbare dienst eenzijdig kan stoppen met het leveren van services. Natuurlijk is het initiële doel om het gebruik van generatieve neurale netwerken mogelijk te maken op locaties waar internettoegang afwezig of moeilijk is (bijvoorbeeld in een vliegtuig).
Het idee was om de lancering, besturing en fijnafstelling van LLM's te vereenvoudigen. In plaats van complexe instructies in meerdere stappen, kun je met Ollama één simpel commando uitvoeren en na enige tijd het eindresultaat ontvangen. Het wordt tegelijkertijd gepresenteerd in de vorm van een lokaal neuraal netwerkmodel, waarmee je kunt communiceren via een webinterface en API voor eenvoudige integratie in andere toepassingen.
Voor veel ontwikkelaars werd dit een zeer nuttig hulpmiddel, omdat het in de meeste gevallen mogelijk was om Ollama te integreren met de gebruikte IDE en aanbevelingen of kant-en-klare code te ontvangen die direct geschreven werd terwijl er aan de applicatie werd gewerkt.
Ollama was oorspronkelijk alleen bedoeld voor computers met het besturingssysteem macOS, maar werd later geport naar Linux en Windows. Er is ook een speciale versie uitgebracht voor het werken in gecontaineriseerde omgevingen zoals Docker. Op dit moment werkt het even goed op desktops als op elke dedicated server met een GPU. Ollama ondersteunt de mogelijkheid om out-of-the-box te schakelen tussen verschillende modellen en maximaliseert alle beschikbare bronnen. Natuurlijk presteren deze modellen misschien niet zo goed op een gewone desktop, maar ze functioneren heel adequaat.
Hoe installeer ik Ollama
Ollama kan op twee manieren worden geïnstalleerd: zonder gebruik te maken van containerisatie, met behulp van een installatiescript, en als een kant-en-klare Docker-container. De eerste methode maakt het makkelijker om de componenten van het geïnstalleerde systeem en modellen te beheren, maar is minder fouttolerant. De tweede methode is fouttoleranter, maar als je deze gebruikt, moet je rekening houden met alle aspecten die inherent zijn aan containers: iets complexer beheer en een andere benadering van gegevensopslag.
Ongeacht de gekozen methode zijn er een aantal extra stappen nodig om het besturingssysteem voor te bereiden.
Voorwaarden
Update de pakketcache repository en geïnstalleerde pakketten:
sudo apt update && sudo apt -y upgradeInstalleer alle benodigde GPU-stuurprogramma's met behulp van de auto-installatiefunctie:
sudo ubuntu-drivers autoinstallStart de server opnieuw op:
sudo shutdown -r nowInstallatie via script
Het volgende script detecteert de huidige architectuur van het besturingssysteem en installeert de juiste versie van Ollama:
curl -fsSL https://ollama.com/install.sh | shTijdens het gebruik maakt het script een aparte ollama gebruiker aan, waaronder de bijbehorende daemon wordt gestart. Overigens werkt hetzelfde script ook goed in WSL2, waardoor de Linux-versie van Ollama op Windows Server kan worden geïnstalleerd.
Installatie via Docker
Er zijn verschillende methodes om Docker Engine op een server te installeren. De eenvoudigste manier is om een specifiek script te gebruiken dat de huidige Docker-versie installeert. Deze aanpak is effectief voor Ubuntu Linux, vanaf versie 20.04 (LTS) tot de nieuwste versie, Ubuntu 24.04 (LTS):
curl -sSL https://get.docker.com/ | shOm Docker-containers goed te laten samenwerken met de GPU, moet een extra toolkit worden geïnstalleerd. Omdat deze niet beschikbaar is in de standaard Ubuntu-repositories, moet je eerst een repository van derden toevoegen met het volgende commando:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.listUpdate de pakketcache repository:
sudo apt updateEn installeer het pakket nvidia-container-toolkit:
sudo apt install nvidia-container-toolkitVergeet niet om de docker daemon opnieuw te starten via systemctl:
sudo systemctl restart dockerHet is tijd om Ollama te downloaden en uit te voeren met de Open-WebUI webinterface:
sudo docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollamaOpen de webbrowser en navigeer naar http://[server-ip]:3000:
De modellen downloaden en uitvoeren
Via de opdrachtregel
Voer gewoon het volgende commando uit:
ollama run llama3Via WebUI
Open Settings > Models, typ de naam van het benodigde model, bijvoorbeeld llama3 en klik op de knop met het downloadsymbool:

Het model wordt automatisch gedownload en geïnstalleerd. Zodra dit voltooid is, sluit u het instellingenvenster en selecteert u het gedownloade model. Hierna kunt u er een dialoog mee beginnen:

VSCode integratie
Als je Ollama hebt geïnstalleerd met behulp van het installatiescript, kun je vrijwel direct alle ondersteunde modellen starten. In het volgende voorbeeld zullen we het standaardmodel uitvoeren dat wordt verwacht door de Ollama Autocoder-extensie (openhermes2.5-mistral:7b-q4_K_M):
ollama run openhermes2.5-mistral:7b-q4_K_MStandaard staat Ollama het werken via een API toe, waarbij alleen verbindingen vanaf de lokale host worden toegestaan. Daarom is voor het installeren en gebruiken van de uitbreiding voor Visual Studio Code, port forwarding vereist. Specifiek moet je poort 11434 doorsturen naar je lokale computer. U kunt een voorbeeld vinden in ons artikel over Easy Diffusion WebUI.
Typ Ollama Autocoder in een zoekveld en klik dan op Install:
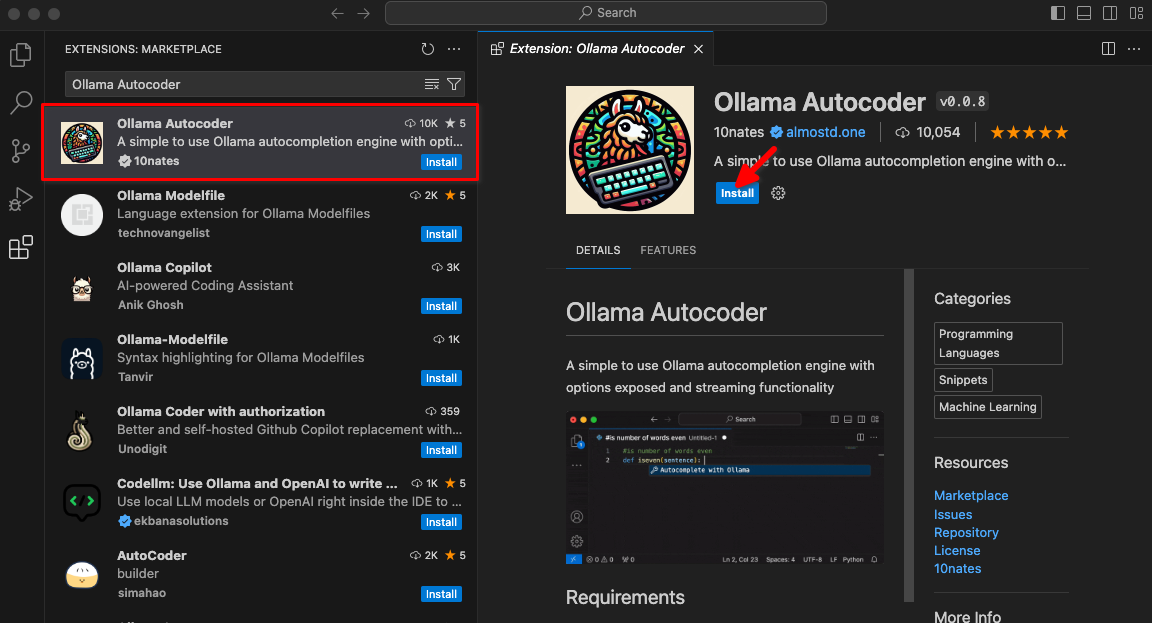
Na het installeren van de extensie zal een nieuw item met de titel Autocomplete with Ollama beschikbaar zijn in het opdrachtenpalet. Begin met coderen en start deze opdracht.
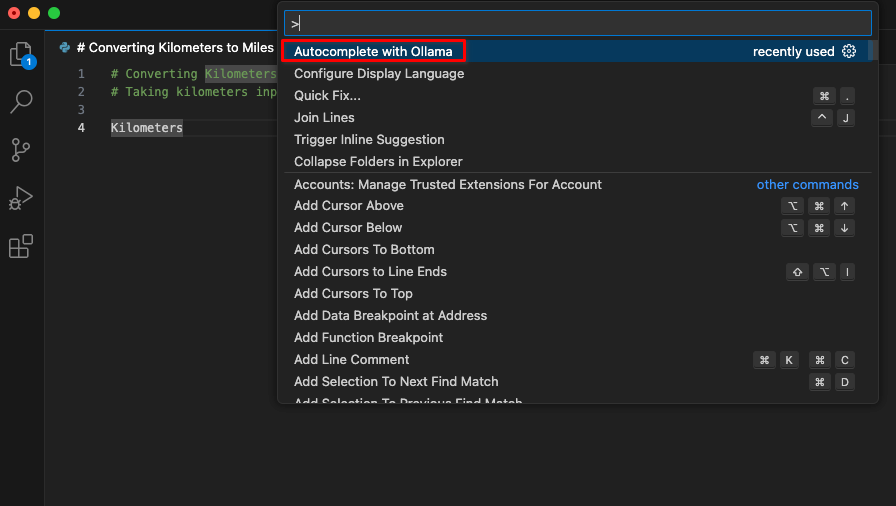
De extensie zal verbinding maken met de LeaderGPU server via port forwarding en binnen enkele seconden zal de gegenereerde code op uw scherm verschijnen:
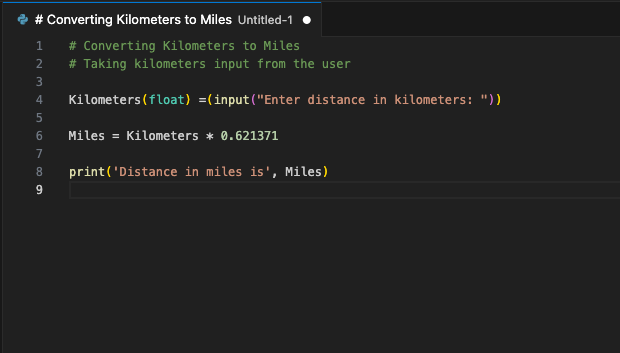
U kunt dit commando toewijzen aan een sneltoets. Gebruik het wanneer u uw code wilt aanvullen met een gegenereerd fragment. Dit is slechts één voorbeeld van de beschikbare VSCode-uitbreidingen. Het principe van port forwarding van een externe server naar een lokale computer maakt het mogelijk om een enkele server op te zetten met een draaiende LLM voor een heel ontwikkelteam. Deze zekerheid voorkomt dat derden of hackers de verzonden code kunnen gebruiken.
Zie ook:
Bijgewerkt: 04.01.2026
Gepubliceerd: 20.01.2025




