





Tensorflow ResNet-50 benchmark
Tensorflow™ ResNet-50 benchmark
LeaderGPU® is een dienst die zich al geruime tijd serieus op de markt voor GPU-computing begeeft. De snelheid van de berekeningen voor het ResNet-50 model in LeaderGPU® is 2,5 keer sneller vergeleken met Google Cloud, en 2,9 keer sneller vergeleken met AWS (gegevens worden verstrekt voor een voorbeeld met 8x GTX 1080 vergeleken met 8x Tesla® K80). De kosten voor het leasen van de GPU per minuut in LeaderGPU® beginnen bij slechts 0,02 euro, wat meer dan 4 keer lager is dan de huurkosten in Google Cloud en meer dan 5 keer lager dan de kosten in AWS (per 7 juli 207).
In dit artikel zullen we het ResNet-50 model testen in populaire diensten zoals LeaderGPU®, AWS en Google Cloud. U zult in de praktijk kunnen zien waarom LeaderGPU® aanzienlijk beter presteert dan de vertegenwoordigde concurrenten.
Alle tests zijn uitgevoerd met python 3.5 en Tensorflow-gpu 1.2 op machines met GTX 1080, GTX 1080 TI en Tesla® P 100 met besturingssysteem CentOS 7 geïnstalleerd en CUDA® 8.0-bibliotheek.
De volgende commando's werden gebruikt om de test uit te voeren:
git clone https://github.com/tensorflow/benchmarks.gitpython3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=?(Number of cards on the server) --model resnet50 --batch_size 32 (64, 128, 256, 512)GTX 1080 instanties
Voor de eerste test gebruiken we instances met de GTX 1080. De testomgevinggegevens (met batchgroottes 32 en 64) staan hieronder:
- Instantietypen: 2x GTX 1080, 4x GTX 1080, 8x GTX 1080
- OS: CentOS 7
- CUDA® / cuDNN: 8.0 / 5.1
- TensorFlow™ GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Opdracht: # python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4,8) --model resnet50 --batch_size 32 (optioneel 64, 128,256, 512)
- Model: ResNet50
- Datum van testen: juni 2017
De testresultaten worden weergegeven in het volgende diagram:

GTX 1080TI instanties
De volgende stap is het testen van instanties met de GTX 1080 Ti. De testomgevinggegevens (met batchgroottes 32, 64 en 128) staan hieronder:
- Instantietypen: ltbv21, ltbv18
- GPU: 2x GTX 1080TI, 4x GTX 1080TI
- OS: CentOS 7
- CUDA® / cuDNN: 8.0 / 5.1
- TensorFlow™ GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Opdracht: # python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 (4) --model resnet50 --batch_size 32 (optioneel 64, 128,256, 512)
- Model: ResNet50
- Datum van testen: juni 2017
De testresultaten worden weergegeven in het volgende diagram:

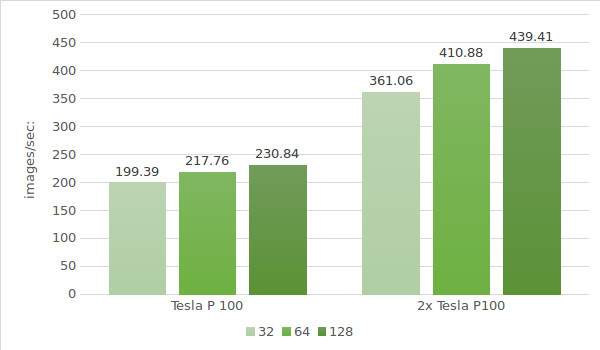
Tesla® P100 instantie
De laatste stap is het testen van instanties met Tesla® P100. Hieronder vindt u gegevens over de testomgeving (met batchgroottes 32, 64 en 128):
- Instance-type: 2x NVIDIA® Tesla® P100
- OS: CentOS 7
- CUDA® / cuDNN: 8.0 / 5.1
- TensorFlow™ GitHub hash: b1e174e
- Benchmark GitHub hash: 9165a70
- Opdracht: # python3.5 benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=2 --model resnet50 --batch_size 32 (optioneel 64, 128, 256, 512)
- Model: ResNet50
- Datum van testen: juni 2017
De testresultaten worden weergegeven in het volgende diagram:
De volgende tabel geeft de testresultaten van Resnet50 weer voor Google cloud en AWS (batchgrootte 64):
| GPU | Google cloud | AWS |
|---|---|---|
| 1x Tesla® K80 | 51.9 | 51.5 |
| 2x Tesla® K80 | 99 | 98 |
| 4x Tesla® K80 | 195 | 195 |
| 8x Tesla® K80 | 387 | 384 |
* De verstrekte gegevens zijn afkomstig van de volgende bronnen:
https://www.tensorflow.org/performance/benchmarks#details_for_google_compute_engine_nvidia_tesla_k80 https://www.tensorflow.org/performance/benchmarks#details_for_amazon_ec2_nvidia_tesla_k80
Laten we de kosten en verwerkingstijd berekenen voor 1.000.000 afbeeldingen op elke machine van LeaderGPU®, AWS en Google. Telling is beschikbaar met een batchgrootte van 64 voor alle machines.
| GPU | Aantal afbeeldingen | Tijd | Prijs (per minuut) | Totale kosten |
|---|---|---|---|---|
| 2x GTX 1080 | 1000000 | 64m 15sec | 0,02 € | 1,29 € |
| 4x GTX 1080 | 1000000 | 34m 17sec | 0,03 € | 1,03 € |
| 8x GTX 1080 | 1000000 | 17m 32sec | 0,09 € | 1,58 € |
| 4x GTX 1080TI | 1000000 | 23m 34sec | 0,04 € | 0,94 € |
| 2х Tesla® P100 | 1000000 | 40m 33sec | 0,08 € | 3,24 € |
| 8x Tesla® K80 Google cloud | 1000000 | 43m 3sec | 0,0825 €** | 3,55 € |
| 8x Tesla® K80 AWS | 1000000 | 43m 24sec | 0,107 € | 4,64 € |
** De Google cloudservice biedt geen betaalplannen per minuut. De kostenberekeningen per minuut zijn gebaseerd op de uurprijs ($ 5,645).
Zoals kan worden geconcludeerd uit de tabel, is de beeldverwerkingssnelheid in het ResNet-50 model het maximum met 8x GTX 1080 van LeaderGPU®, terwijl:
- De initiële leasekosten bij LeaderGPU® beginnen al bij € 1,28, wat ongeveer 2,77 keer lager is dan bij de instances van 8x Tesla® K80 van Google Cloud, en ongeveer 4,38 keer lager dan bij de instances van 8x Tesla® K80 van Google AWS;
- de verwerkingstijd was 17 minuten 32 seconden, wat 2,5 keer sneller is dan in de 8x Tesla® K80 instances van Google Cloud, en 2,49 keer sneller dan in de 8x Tesla® K80 instances van Google AWS.
LeaderGPU® presteert aanzienlijk beter dan zijn concurrenten, zowel op het gebied van servicebeschikbaarheid als beeldverwerkingssnelheid. Huur een GPU met een betaling per minuut in LeaderGPU® om verschillende taken in de kortste tijd op te lossen!
LEGAL WARNING:
PLEASE READ THE LICENSE FOR CUSTOMER USE OF NVIDIA® GEFORCE® SOFTWARE CAREFULLY BEFORE AGREEING TO IT, AND MAKE SURE YOU USE THE SOFTWARE IN ACCORDANCE WITH THE LICENSE, THE MOST IMPORTANT PROVISION IN THIS RESPECT BEING THE FOLLOWING LIMITATION OF USE OF THE SOFTWARE IN DATACENTERS:
«No Datacenter Deployment. The SOFTWARE is not licensed for datacenter deployment, except that blockchain processing in a datacenter is permitted.»
Customer may use the LeaderGPU® Services for blockchain processing.
BY AGREEING TO THE LICENSE AND DOWNLOADING THE SOFTWARE YOU GUARANTEE THAT YOU WILL MAKE CORRECT USE OF THE SOFTWARE AND YOU AGREE TO INDEMNIFY AND HOLD US HARMLESS FROM ANY CLAIMS, DAMAGES OR LOSSES RESULTING FROM ANY INCORRECT USE OF THE SOFTWARE BY YOU.
Bijgewerkt: 04.01.2026
Gepubliceerd: 07.12.2017